

이 글에는 https://eatch.dev/s/iter 링크를 통해서도 접속할 수 있습니다.
이 글의 인터랙티브 콘탠츠는 데스크톱 환경에 최적화되어 있으며, 모바일 환경에서 사용하기 어려울 수 있습니다.
에츠허르 데이크스트라Edsger W. Dijkstra는 번호 붙이기를 0부터 시작해야 하는 이유Why numbering should start at zero라는 글을 남긴 적이 있습니다. 전체 내용은 별도의 보충글에 정리해 두었고, 이 중 글과 관련이 있는 부분을 발췌하면 이렇습니다.
자연수의 부분수열 2, 3, ..., 12를 위험천만한 줄임표 없이 나타낼 때, 다음 4종류의 방식 중 하나를 고를 수 있다.
(중략)
자연수에는 최솟값이 존재한다. b와 d와 같이 하한을 제외할 경우 가장 작은 자연수부터 시작하는 부분수열의 하한이 비자연수가 되어야 한다. 이는 더러우니 하한은 a와 c처럼 ≤로 표기하는 것을 선택한다. 한편 가장 작은 자연수부터 시작하는 부분수열을 생각하자. 상한을 포함할 경우 부분수열이 빈 수열이 되었을 때 상한이 비자연수가 되어야 한다. 이는 더러우니 상한은 a와 d처럼 <로 표기하는 것을 선택한다. 이로써 방식 a를 가장 우선하는 것으로 결론지을 수 있다.
처음 접하면 다소 비직관적일 수 있는 C++의 반복자 역시 이 글의 내용으로 어느 정도 설명할 수 있습니다. 하지만...
- 왜
범위인가? - 위 글에서 하한을 포함하고 상한을 제외하는 방식 a가 가장 합리적임을 설명했습니다.
- 끝점 너머past-the-end 반복자는 왜 있는가?
- 방식 a의 상한값에서 끝점 너머 반복자를 자연스럽게 유추할 수 있습니다. 반복문에서 탈출 조건을 확인하기 편하다는 장점 역시 있습니다.
std::lower_bound와std::upper_bound의 정의는 대체 왜 그런가?- 이렇게 정의해야
std::equal_range가 반환하는 범위가 방식 a와 일치하기 때문입니다.
- 이렇게 정의해야
- 역방향 반복자를 역참조하면 왜 한 칸 앞을 가리키는가?
- ?????? 한 칸 앞이라고요????????????
참고
std::lower_bound와 std::upper_bound의 정의
std::lower_bound와 std::upper_bound가 어떻게 정의되어 있는지 궁금하시다면 cppreference.com의 정의를 참고할 수 있습니다. 이때 (어떤 조건 f에 대해) 분할되었다partitioned는 것은 어떤 점을 기준으로 왼쪽의 모든 원소 l에 대해 f(l)이 참, 오른쪽의 모든 원소 r에 대해 f(r)이 거짓임을 의미합니다.
[
value를 기준으로] 분할된 범위 [first,last)에서value앞에 오지 않는 첫 원소를 찾는다.
분할된 범위 [
first,last)에서value뒤에 오는 첫 원소를 찾는다.
역방향 반복자에 대한 설명까지 날로 먹을 수는 없었습니다.
이 네 가지 의문점이 제가 C++의 STL을 처음 배우면서 가장 헷갈렸던 부분인데, 네이버 블로그를 사용하던 시절에 같은 주제로 글을 올린 적이 있습니다. 물론 역방향 반복자에 대해서도 '한 칸 앞을 참조해야 .end()를 시작점으로, .begin()을 끝점 너머로 재사용할 수 있다'는 설명을 할 수 있지만, 이 글에서는 반복자를 이해하는 조금 더 통합적인 시각을 제시하려고 합니다.
다른 멘탈 모델로 보기
모르는 개념을 새로 배울 때는 이미 알던 개념을 멘탈 모델로 삼아 비유하는 것이 큰 도움이 됩니다. 제가 반복자를 처음 배울 때 만들었던 멘탈 모델은 마인크래프트 핫바였습니다.
제가 만들었던 비유는 다음과 같습니다.
- 역참조 (읽기/쓰기 연산) = 아이템 확인, 장착, 사용
- 증감 = 마우스 휠
- 임의 접근 = 단축키 1~9
사실 이렇게 의식적으로 생각하면서 멘탈 모델을 정했다기보다는 그동안 마인크래프트를 했던 경험이 쌓여 반복자를 배우자마자 무의식적으로 연결된 것에 가깝습니다.
유감스럽게도 이 멘탈 모델은 완벽하지 않고, 자연스럽게 위 단락에서 제시했던 네 가지 의문점을 가지게 됩니다.
- 왜
범위인가? - 마인크래프트 핫바는 애초에 한 칸씩만 선택할 수 있기 때문에 범위의 개념이 없습니다.
- 끝점 너머 반복자는 왜 있는가?
- 마인크래프트 핫바에는 '끝점 너머'의 칸이 있지도 않고, 선택할 수도 없습니다.
std::lower_bound와std::upper_bound의 정의는 대체 왜 그런가?- 마인크래프트: "그게 뭔데요"
- 역방향 반복자를 역참조하면 왜 한 칸 앞을 가리키는가?
- 마인크래프트: "그게 뭔데요 (2)"
결국 저는 반복자를 더 직관적으로 이해하기 위해 다른 멘탈 모델을 찾기 시작했고, 그 결과가 위에서 링크한 구 블로그 글입니다. 당시의 글에서 제시했고 지금도 사용하고 있는 멘탈 모델은 텍스트 에디터의 커서입니다. 지금부터는 커서로 어떻게 반복자를 설명할 수 있는지 하나씩 짚어보겠습니다.
참고
이 글에서는 마우스 포인터(역시 '커서')나 인공지능 기반 IDE 커서Cursor를 다루지 않으며, '커서'라고 하면 항상 텍스트 커서를 의미합니다.
가·감산
C++의 반복자 분류 중 이 글과 관련이 있는 것은 가장 포괄적인 것부터 다음과 같은 4(+1)종류입니다.
- 읽기 연산이 가능한 입력 반복자input iterator
- 쓰기 연산이 가능한 출력 반복자output iterator
- 다음 칸으로 움직일 수 있는 순방향 반복자forward iterator
- 순방향 반복자가 되려면 입력 반복자를 만족해야 합니다.
- 이전 칸으로 움직일 수 있는 양방향 반복자bidirectional iterator
- 양방향 반복자가 되려면 순방향 반복자를 만족해야 합니다.
- 임의 접근이 가능한 임의 접근 반복자random-access iterator
- 임의 접근 반복자가 되려면 양방향 반복자를 만족해야 합니다.
이 글에서는 증감 연산부터 다루도록 하겠습니다.
에디터를 클릭하고 키보드로 커서를 움직여 보세요. 배열이 진해진 상태라면 포커스가 잘 들어왔다는 의미입니다.
아마도 이게 어딜 봐서 반복자냐고 하실 분들이 있을지도 모르겠습니다. (자료구조를 가리키는) 반복자라면 무릇 무언가를 가리키고 있어야 할 텐데, 지금 이 커서가 도대체 무엇을 가리키고 있나요? 문자와 문자 사이?
사실 이 글에서 읽기 연산보다도 증감 연산을 먼저 다룬 것은, 커서를 움직일 수 없는 텍스트 에디터는 상상하기조차도 어렵기 때문에 설명의 편의를 위해 부득이하게 순서를 바꿨기 때문입니다. 바로 다음 단락에서 읽기 연산을 설명드릴 테니 일단 들어보세요. 좌우 방향키로 커서를 이동하는 것이 반복자의 증감 연산에 대응한다는 것까지 의심하시지는 않으리라고 믿겠습니다.
읽기 연산
아래아한글을 써보신 경험이 있다면 삽입insert 모드와 수정overtype 모드라는 개념을 들어보았을 것이라고 생각합니다. '제대로 된' 웬만한 텍스트 에디터에는 모두 있는 기능인데, Visual Studio Code는 의외로 출시된 지 9년 7개월(!!)이 지나서야 지원하기 시작했습니다.
삽입 모드는 우리가 항상 사용하는 친숙한 모드로, 문자를 입력하면 문자와 문자 사이에 삽입insert됩니다. 한편 수정 모드로 진입하면 세로선 모양이었던 커서가 블록 모양이 되어 원래 위치 바로 뒤의 문자가 깜박이고, 이때 문자를 입력하면 깜박이는 문자가 지워지고 새로운 문자로 덧씌워집니다overtype. 이 깜박이는 문자가 바로 반복자가 가리키는 데이터입니다. 아까 보았던 인터랙티브 에디터에 수정 모드 기능을 추가해 보겠습니다.
수정 모드를 켠 채로 커서를 끝점으로 움직여보면 커서가 블록 모양을 유지하지 않고 세로선 모양으로 돌아오는 것을 볼 수 있습니다. '다음 문자'가 없기 때문인데, 잠깐 생각해보면 바로 이 위치가 끝점 너머 반복자라는 것을 알 수 있습니다.
임의 접근
임의 접근 반복자는 증감 연산자로 한 칸씩만 이동하는 대신 덧·뺄셈 연산자로 임의 칸만큼 이동할 수 있는데, Vim을 제외하면 이런 기능을 지원하는 에디터는 거의 없습니다. 그 대신 여기서는 마우스 클릭으로 원하는 위치에 커서를 가져다놓는 것에 대신 비유할 수 있겠습니다.
쓰기 연산
에디터(editor)라고 했으니 더 미루지 말고 편집 기능을 추가해 보겠습니다(마참내!). 여기서는 0부터 9까지의 숫자를 입력할 수 있으며, 위에서 소개한 삽입 모드와 수정 모드 이외에도 다른 모드를 하나 더 지원하고 각각 C++에서 지원하는 반복자 연산에 비유할 수 있습니다.
- 수정 (커서 고정) 모드는 일반적인 수정 모드처럼 키를 입력하면 현재 커서로 가리키는 숫자가 수정되지만, 커서가 앞으로 진행하지는 않습니다.
- 가장 기본적인
*i = x;와 비슷한 동작을 합니다. 단, 여기서는 설명을 위해 끝점 너머 위치에 입력하면 비정의 동작이 되는 대신 맨 뒤에 새로운 숫자가 삽입됩니다.
- 가장 기본적인
- 수정 (커서 이동) 모드는 일반적인 수정 모드와 같고, 입력할 때마다 커서가 앞으로 진행하는 것도 같습니다.
*i++ = x;와 비슷한 동작을 합니다.
- 삽입 모드는 일반적인 삽입 모드와 같고, 입력할 때마다 커서가 앞으로 진행하는 동시에 그 뒤의 모든 숫자가 한 칸씩 밀려납니다.
std::insert_iterator(cf.std::inserter)를 통해 삽입하는 것과 비슷한 동작을 합니다. 두 가지 특수한 경우로 커서가 시작점에 있으면std::front_insert_iterator(cf.std::front_inserter), 끝점 너머에 있으면std::back_insert_iterator(cf.std::back_inserter)가 됩니다.
조작 설명이 점점 길어지고 있으니 다음부터는 기본적으로 접어 두도록 하겠습니다. 설명을 확인하려면 에디터 아래의 '▶ 조작' 부분을 누르면 됩니다.
역방향 반복자
반복자의 기본 연산을 모두 다뤘으니 지금부터는 심화된 동작을 다뤄보도록 하겠습니다.
std::reverse_iterator (cf. std::make_reverse_iterator)로 만드는 역방향 반복자의 가장 이상한 점은 역참조(*it)했을 때 한 칸 앞의 원소를 가리킨다는 점인데, 지금까지 다룬 커서 비유로 따지면 수정 모드로 진입했을 때 깜박이는 문자가 커서 오른쪽이 아니라 왼쪽이 되는 꼴과 같습니다. 그런데 왜 애초에 커서 오른쪽 문자가 깜박일까요? 글을 쓸 때 왼쪽에서 오른쪽으로 쓰기 때문에 다음으로 편집할 내용인 오른쪽 문자가 자연스럽게 선택되는 것은 아닐까요?
저를 포함해서 이 블로그의 독자분들은 좌횡서left-to-right 문자 체계에(만) 익숙할 것이라고 생각하는데, 거꾸로 오른쪽에서 왼쪽으로 쓰는 우횡서right-to-left 문자 체계도 있습니다. 아랍 문자와 히브리 문자가 대표적인 예시고, W3C에서는 2025년 6월 12일 기준 12개의 우횡서 문자 체계를 제시하고 있습니다. 우횡서 문자 체계로도 컴퓨터를 사용할 수 있어야 하기 때문에 텍스트 에디터도 여기에 대응하고 있는데, 좌횡서 문자 체계를 사용할 때와 다른 점은 다음과 같습니다.
- 커서가 오른쪽에서 시작하고 글을 쓰면 왼쪽으로 움직인다.
- Home 키를 누르면 커서가 가장 오른쪽으로, End 키를 누르면 커서가 가장 왼쪽으로 움직인다.
- 우횡서 텍스트는 논리적으로 오른쪽에서 시작하고 왼쪽에서 끝나기 때문입니다.
- 커서에 방향 표시가 생기는 경우도 있다.
- 지원하는 소프트웨어에서는 커서가 진행하는 방향으로 가로선이 추가로 그어집니다. 좌횡서에서는 오른쪽, 우횡서에서는 왼쪽에 방향 표시가 있습니다.
- 직접 확인해보고 싶다면 파이어폭스에서
about:config를 열고bidi.browser.ui를true로 바꾸면 됩니다.
그러면 과연 우횡서 문자 체계를 쓰다가 수정 모드로 진입하면 커서의 왼쪽 문자가 깜박일까요? 네!!!
참고로 위의 움짤에서 커서가 잠깐 순간이동하는 것처럼 보이는 것은 좌횡서가 주인 텍스트 안에 우횡서 텍스트가 포함되어 있는 것으로 판정되었기 떄문으로 보입니다.
(사실 위의 움짤을 찍으려고 우횡서와 수정 모드 커서를 모두 지원하는 소프트웨어를 찾아서 한참을 헤맸습니다. 사용한 소프트웨어는 GIMP 3.0입니다.)
지금까지의 내용으로 미루어보아 역방향 반복자는 같은 자료구조를 좌횡서 대신 우횡서 관점으로 보는 것에 비유할 수 있겠습니다. 아래의 텍스트 에디터에서는 Ctrl+R로 좌횡서(정방향)와 우횡서(역방향)를 전환할 수 있고, 커서의 방향 표시로 현재 사용 중인 방향을 확인할 수 있습니다. 실제 텍스트 에디터의 우횡서 동작을 최대한 비슷하게 모사하려고 노력하긴 했는데 잘못 구현했다면 꼭 알려주세요.
범위 지정
마지막으로 다룰 것은 반복자를 사용한 범위 지정입니다. C++에서는 자료구조 안의 범위를 표현할 때 반복자 2개를 사용해 시작과 끝을 표현하는데, 이는 텍스트를 블록 지정하는 것에 비유할 수 있습니다. 사실 블록 지정을 한다고 커서가 2개 생기는 것은 아니지만(Visual Studio Code 등 진짜 멀티커서를 지원하는 텍스트 에디터도 있습니다), 에디터 내부에서는 커서의 위치를 정수 하나로 표현했듯 선택한 범위의 시작점과 끝점 역시 정수 하나씩으로 표현할 수 있다는 점에서 유효한 비유라고 생각합니다.
아래 에디터에도 범위 지정 기능을 추가해 두었고, Shift 키나 마우스 드래그로 원하는 범위의 텍스트를 선택할 수 있습니다.
범위 연산
보통 텍스트 에디터에서 블록 지정을 하면 무슨 작업을 하나요?
- 삭제 (아무래도 백스페이스 한 번으로 범위 전체를 삭제하는 게 꾹 누르고 있는 것보다 편하긴 하죠)
- 복사/붙여넣기
- 리치 텍스트 편집
- 굵게
- 기울임꼴
- 밑줄
- 글자 색상
이외에도 여러 가지 기능을 지원할 수 있는데, 이런 블록 편집 기능은 C++에서는 반복자 범위를 받는 알고리즘 함수에 대응합니다. 아래 에디터에서는 C++의 여러 가지 알고리즘 함수 중 일부를 구현해 두었습니다. 영역을 선택한 상태에서...
- Ctrl+0~9로
std::find - Ctrl+F로
std::reverse(F는 Find의 F가 아니라 Flip의 F입니다.) - Ctrl+U로
std::unique(인접한 중복 원소만 제거됩니다.) - Ctrl+S로
std::random_shuffle(S는 Save의 S가 아니라 Shuffle의 S입니다.)
상한과 하한
이쯤에서 std::lower_bound와 std::upper_bound의 정의를 한 번 더 살펴보기로 하겠습니다.
참고
std::lower_bound와 std::upper_bound의 정의
std::lower_bound와 std::upper_bound가 어떻게 정의되어 있는지 궁금하시다면 cppreference.com의 정의를 참고할 수 있습니다. 이때 (어떤 조건 f에 대해) 분할되었다partitioned는 것은 어떤 점을 기준으로 왼쪽의 모든 원소 l에 대해 f(l)이 참, 오른쪽의 모든 원소 r에 대해 f(r)이 거짓임을 의미합니다.
[
value를 기준으로] 분할된 범위 [first,last)에서value앞에 오지 않는 첫 원소를 찾는다.
분할된 범위 [
first,last)에서value뒤에 오는 첫 원소를 찾는다.
지금까지 보았던 반복자의 커서 비유에서 어떤 원소 x를 가리키는 반복자는 x보다 앞에 오는 부분과 x를 포함해서 x보다 뒤에 오는 부분을 분할하는 것으로도 볼 수 있습니다. 이를 염두에 두고 '앞에 온다'와 '뒤에 온다'를 각각 '미만'과 '초과'를 의미하는 것으로 생각하면 위의 정의는 다음과 같이 해석할 수 있습니다.
std::lower_bound는value미만인 부분과value미만이 아닌, 즉 이상인 부분을 분할합니다.std::upper_bound는value를 초과하지 않는, 즉 이하인 부분과value를 초과하는 부분을 분할합니다.
즉, std::lower_bound와 std::upper_bound의 순서쌍을 반환하는 std::equal_range는 주어진 범위를 value 미만인 부분, value와 동일한 부분, value를 초과하는 부분으로 3분할하는 것으로 생각할 수 있고, 반환되는 두 반복자로 이루어진 범위는 value와 같은 부분에 해당한다는 것을 직관적으로 이해할 수 있습니다.
아래의 정렬-미리된 배열™에서 Ctrl+Shift+0~9를 입력해서 그 숫자만큼의 std::equal_range를 실행해볼 수 있습니다. 혹시 주어진 숫자의 분포가 너무 치우쳐 있거나 다른 배열에서 실험해 보고 싶다면 왼쪽 아래의 다시 생성 버튼을 누르면 됩니다.
복습해보기
지금까지 언급했던 모든 내용을 정리해 봅시다. 마인크래프트 핫바보다 텍스트 커서가 반복자를 훨씬 더 잘 설명할 수 있었습니다.
- 역참조 (읽기/쓰기 연산) = 텍스트 확인, 입력
- 특히 수정 모드에서 깜박이는 문자가 반복자를 역참조할 때 나오는 값에 대응합니다.
- 증감 = 좌우 방향키로 이동
- 임의 접근 = 마우스로 이동
- 특히 Vim의 경우 임의의 정수
<n>에 대해<n>h와<n>l
- 특히 Vim의 경우 임의의 정수
- 범위 지정 = 텍스트 선택
- 범위를 입력받는 알고리즘 함수 = 선택된 텍스트를 블록 단위로 편집
- 역방향 반복자 = 우횡서 언어 체계
마지막으로 아래의 에디터에는 지금까지 소개한 모든 기능을 모두 켜 두겠습니다. Ctrl+Shift+0~9를 입력하면 선택하기 전에 텍스트 전체에 대해 먼저 정렬을 수행합니다.
지금까지 커서 멘탈 모델이 정말 효과적이었던 탓인지 현재의 저는 프로그래밍 언어 안에서 범위를 지정할 때 가능한 한 무조건 a 방식을 사용하고(c 방식을 사용하는 Haskell 리스트 문법은 각성하라), 심지어는 C에서도 포인터를 C++ 반복자를 쓰는 느낌으로 사용합니다. (저는 백준 주력 언어가 C++가 아니라 C입니다!)
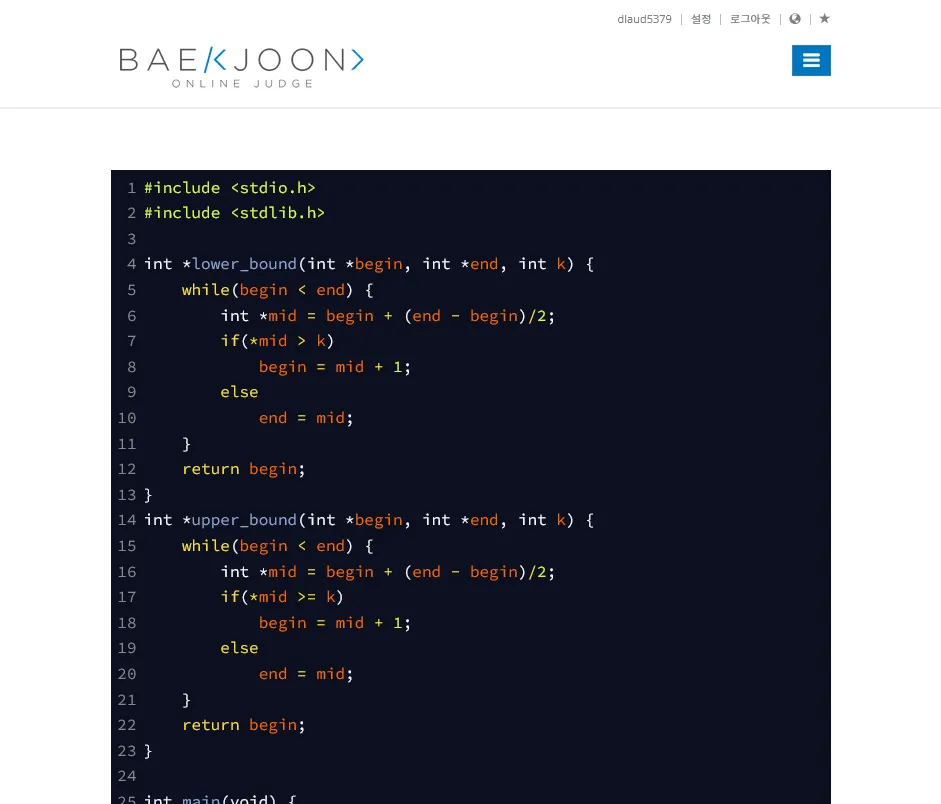
아무튼 제 결론은 이렇습니다. 커서 멘탈 모델 받아들이고 광명 찾자
이 글을 작성하는 데 생성형 AI를 다음과 같이 사용했습니다.
간접 사용
Claude를 사용해 임의 칸만큼 커서 이동 명령을 지원하는 텍스트 에디터의 종류에 대해 보조 조사를 진행했습니다.