
이 글에는 https://eatch.dev/s/ctype 링크를 통해서도 접속할 수 있습니다.
C로 코딩을 할 때, 가장 '올바른' 코딩 스타일은 무엇일까요?
int*x;int* x;int *x;int * x;
물론 정답은 없습니다. 코딩 스타일이 원래 스페이스냐 탭이냐로 싸우는 주제인걸요. 물론 스페이스 3칸 너비의 탭(???)이나1 int*x;처럼 누가 봐도 오답인 것이 있긴 합니다.
이 글을 이런 질문으로 시작하는 이유가 있는데, 2020년 12월에 "int* x;는 틀리고 int *x;가 맞다"는 논지의 글을 쓰려다 정신을 차려보니 제가 아는 C의 타입 시스템을 통째로 다룬 글을 써버렸기 때문입니다. 이 글은 개발 블로그를 새로 개발하면서 약 4년만에 재작성한 버전입니다. 일단 쓰고 나니 이리저리 흩어져 있던 C라는 언어에 관한 지식을 통합적으로 이해하는 기틀을 다질 수 있었고 미래의 저 자신이 참고할 수 있는 자료로도 많이 도움이 됐는데, 이번 재작성으로 더 읽기 쉽고 많은 도움이 되었으면 좋겠습니다.
C의 타입 시스템은 제가 처음 생각했던 것보다 언어의 꽤 큰 부분을 차지합니다. C의 타입 시스템을 잘 이해하면 할 수 있는 것들을 몇 가지 적자면 이렇습니다. 아래의 7가지 떡밥은 글이 끝나기 전에 전부 회수할 것을 약속드립니다.
- 왜
int* x;가 틀리고int *x;가 맞는지 설명할 수 있다. typedef를 자유자재로 사용할 수 있다.const int *x;와int const *x;와int * const x;의 차이를 이해할 수 있다.int *(*(*x)(char *))[64];와 같은 헷갈리는 선언을 그나마 쉽게 읽을 수 있다.- 그런데 웬만하면 이런 식으로 선언하지 말고
typedef를 써 주세요.
- 그런데 웬만하면 이런 식으로 선언하지 말고
- 왜 다차원 배열의 맨 처음 길이만 생략할 수 있는지 이해할 수 있다.
- 배열과 포인터가 정확히 어떻게 다른지 이해할 수 있다.
- 단 한 번의
malloc호출로 다차원 배열을 동적 할당받을 수 있다.
참고
- C의 타입 시스템에서 제가 설명할 수 있을 정도로 이해한 모든 부분을 적당히 얕게(치트시트로 활용할 수 있을 정도로) 설명합니다. 더 깊은 세부사항은 검색해서 확인해 주세요. cppreference.com의 자료를 권장드립니다.
- 제가 C의 타입 시스템을 완전히 이해하지는 못했기 때문에 어쩔 수 없이 빠진 부분이 있습니다. 현재 타입별 크기와 정렬, C11
_Alignas, C11_Atomic은 다루고 있지 않습니다. - 번역어로 어느 정도 통용되는 단어와 제가 임의로 번역한 번역어가 어느 정도 섞여 있습니다. 검색에 도움이 되도록 대부분의 용어에 원어를 병기하고, 원어로부터 매우 쉽게 유추할 수 없는 임의 번역어는 별표(*)로 표기했습니다.
- 제가 C의 타입 시스템을 완전히 이해하지는 못했기 때문에 어쩔 수 없이 빠진 부분이 있습니다. 현재 타입별 크기와 정렬, C11
- C에 대한 어느 정도의 기초 지식을 가정합니다. C를 처음 배우시는 분이라면 아쉽지만 어느 정도 언어에 익숙해진 뒤 다시 찾아와 주세요.
- 업데이트할 것이나 빠진 것이 생기면 제가 그때그때 찾아와서 업데이트할 예정입니다. 글의 맨 위에 수정한 날짜가 있으니 자주 찾아와서 바뀐 것이 있는지 확인해 보세요.
- 글의 구조는 전체를 순서대로 읽는 것보다는 필요한 부분을 발췌독할 때에 초점을 맞추어 구성했으며, 순서대로 읽을 경우 이후 내용에서 언급하는 사전 지식을 놓칠 수 있습니다. 소제목 링크가 있다면 해당 내용을 먼저 읽어주세요.
- 코드 블록 안의 코드가 파일 범위인지 블록 범위인지는 따로 표기하지 않지만, 구분이 필요할 경우 주변 맥락에서 유추할 수 있습니다.
- 코드 블록 안에 작성한 이모지의 의미는 다음과 같습니다.
- ✅: 올바르게 컴파일 및 실행되는 코드입니다.
- ✅👎: 올바르게 컴파일 및 실행되는 코드이지만 권장되지 않는 코딩 스타일을 사용하고 있습니다.
- 🔥: 컴파일이 되지만 논리적인 오류가 있는 코드입니다.
- ❌: 원칙적으로 컴파일이 되지 않는 코드입니다. 컴파일러에서 언어 확장을 지원할 경우 컴파일이 될 수도 있습니다.
배경지식: 그대들은 무슨 개정판으로 코딩할 것인가
본격적으로 시작하기 전에 잠깐 C의 역사 얘기를 하겠습니다.
C는 1972년에 벨 연구소의 데니스 리치Dennis Ritchie가 처음 개발했는데, 그 당시에는 C 표준이 아직 없어서 1978년에 브라이언 커니핸Brian Kernighan과 공저한 The C Programming Language가 사실상의 표준 역할을 했습니다. 이 시절의 C '표준'을 저자 이름의 앞글자를 따서 K&R C라고도 합니다. (재미있는 사실! 이 책은 "hello, world"의 대중화에도 결정적인 영향을 미쳤습니다.)
이후 C의 규격이 국제 표준으로 확립된 것은 1989년이 되어서였고(이 표준을 C89나 C90, ANSI C라고도 합니다), 이후 C95, C99, C11, C17, C23까지 5번의 개정을 거쳤습니다. C17은 기능 추가 없이 기존 표준의 결함만 수정하였고, 현재 작업 중인 다음 개정판에는 C2Y라는 가제가 붙어 있습니다.
여기서 언급한 C의 표준 개정판이 언어 사용에 큰 영향을 미치는데, 예를 들어 C99 이전까지는 for문의 초기화 절 안에서 변수를 선언할 수 없었습니다.
// ❌ C99 이전의 개정판에서는 `for`문의 초기화 절에서 변수를 선언할 수 없습니다.
for(int i = 0; i < 8; i++)
printf("%d\n", i);위와 같은 이유로 이 글에서도 필요한 곳에 표준 개정판 표기를 삽입하고 있습니다. 예를 들어 C11은 C11에 추가된 기능이라는 의미입니다. 다른 표준 개정판을 사용하려면 컴파일러에 플래그를 넣어주세요. 아래 플래그는 GCC/Clang 기준입니다.
- C89:
-ansi혹은-std=c90 - C95:
-std=iso9899:199409 - C99:
-std=c99 - C11:
-std=c11 - C17:
-std=c17 - C23:
-std=c23 - 두 컴파일러 모두 표준을 심각하게 위배하지 않는 한도 내에서 일부 언어 확장을 지원하고 있으며, 위의 플래그에서
c를gnu로 바꾸어 활성화할 수 있습니다.
컴파일러를 직접 다루지 않는 IDE 환경이라도 웬만하면 설정에서 컴파일러 플래그나 표준 개정판을 설정할 수 있습니다. IDE별로 구체적인 방법은 해당 IDE의 문서를 읽거나 검색해서 확인해볼 수 있습니다.
표준 문서를 직접 읽어보려면
C의 표준(C23)은 로 등록되어 있고, 2025년 3월 3일 현재 221 스위스 프랑(한화 약 35만 7천 원)으로 판매하고 있으며, 이전 개정판은 ANSI에서 판매하고 있습니다.
그 대신 C99부터 C23까지의 최종안은 무료로 열람 가능합니다. 이 글도 C23의 최종안인 N3220을 참고하여 작성했습니다.
배경지식: 표준에서 정하지 않는 것들
주의
이 단락에는 오개념이 있을 수 있습니다. 잘못된 내용을 찾으셨다면 꼭 알려주세요.
추가로, C 표준(이하 "표준")에서는 언어의 모든 세부사항을 완전히 못박아두지 않으며, 대표적으로 다음 네 종류의 '표준에서 정하지 않는 것들'을 통해 컴파일러가 컴파일 과정에서 다른 동작을 보이거나, 코드를 최적화하거나, 언어 확장을 구현할 재량을 어느 정도 보장합니다.
-
비정의 동작*undefined behavior: 거칠게 말하면 '잘못되었지만' 일단 컴파일은 되는 동작이라고 설명할 수 있습니다. 비정의 동작이 있는 프로그램이 어떻게 실행되는지에 대해서는 표준에서 아무런 제한도 두지 않으므로 프로그래머가 의도한 무언가를 하든, 오류를 일으키든, 컴퓨터를 조용히 포맷해버리든 이론상으로는 문제가 없습니다.2
비정의 동작
이식 불가능하거나 잘못된 프로그램 구조 혹은 잘못된 데이터를 사용할 때의 동작으로서, 본 문서가 어떠한 요구사항도 적용하지 않는 것
- 예제 비정의 동작의 예로는 널 포인터를 역참조할 시의 동작이 있다.
-
비명시 동작*unspecified behavior: '잘못된' 것은 아니고 상식선 안의 동작을 하지만, 실제로 어떤 동작을 하는지 표준에서 정하지 않는 것을 말합니다. 비정의 동작과 달리 비명시 동작이 생기더라도 표준의 다른 조항은 계속 적용됩니다.
비명시 동작
비명시 값을 사용함으로 인한 동작, 혹은 본 문서에서 둘 이상의 가능성을 허용하고 어떠한 경우에도 무엇을 선택하는지에 대해 추가적인 요구사항을 적용하지 않는 기타 동작
- 예제 비명시 동작의 예로는 함수의 인자가 평가되는 순서가 있다.
-
구현체 정의 동작*implementation-defined behavior: 비명시 동작과 같이 실제로 어떤 동작을 하는지 표준에서 명시하지 않는 동작이지만, 구현체에서 해당 내용을 문서화해야 합니다.
구현체 정의 동작
비명시 동작으로서 각 구현체가 어떤 선택을 하는지 문서화하는 것
- 예제 구현체 정의 동작의 예로는 부호 있는 정수의 우측 시프트 시 최상위 비트의 전파 방식이 있다.
-
로케일 특정 동작*locale-specific behavior: 로케일(지역이나 언어 등)에 따라 달라지는 동작으로, 구현체 정의 동작과 같이 구현체에서 해당 내용을 문서화해야 합니다.
로케일 특정 동작
지역의 국가, 문화, 언어 관습에 의존하는 동작으로서 각 구현체가 문서화하는 것
- 예제 로케일 특정 동작의 예로는
islower함수가 26개의 로마자 소문자 이외의 문자에 대해 참을 반환하는지의 여부가 있다.
참고
'구현체'의 의미에 관하여
표준에서는 [C 표준을 구현하는] '구현체implementation'를 다음과 같이 정의하고 있습니다. 이 글에서는 그냥 '컴파일러'와 같은 말이라고 생각해도 되지만, 실제로는 컴파일되는 과정과 실행되는 환경을 아우르기 때문에 그것보다는 더 복잡합니다.
구현체
특정한 제어 설정이 적용된 특정한 번역 환경에서 실행되는 특정한 소프트웨어의 집합으로서, 특정한 실행 환경에서 실행되도록 프로그램 번역을 수행하고 그러한 환경에서 함수의 실행을 지원하는 것
모든 환경과 모든 컴파일러에서 똑같이 돌아갈 것이라고 믿고 이런 동작을 함부로 구현했다가는 나쁜 일이 생길 수 있으니 유의해야 합니다. 무엇을 언제 써도 되는지는 웬만하면 아래를 참고하면 될 것이라고 생각합니다.
- 구현체 정의 동작: 자유롭게 사용해도 되지만, 구현체의 문서(어렵다면 인터넷에서 그 주제에 대한 글을 읽어서라도)를 어느 정도 숙지하고, 이식성이 중요하다면 지나치게 의존하지 않는 것이 좋습니다.
- 비명시 동작: 써도 되지만, 문서화의 의무가 없는 만큼 추가로 무언가를 가정하지 않는 것이 좋습니다.
- 비정의 동작: 최대한 피하세요. 이쪽은 [옳고] 그름의 문제에 더 가까운 만큼 비정의 동작을 안 만드는 프로그램을 작성하는 것에 익숙해지는 것이 좋습니다.
- 단, 비정의 동작에 해당하는 언어 기능에 컴파일러가 언어 확장으로 의미를 부여하는 경우가 있습니다. 이 경우에는 구현체 정의 동작에 준하여 사용하는 것이 좋습니다.
선언문declaration
참고
여기서 1번 떡밥을 부분적으로 회수합니다.
왜
int* x;가 틀리고int *x;가 맞는지 설명할 수 있다.
C에서 타입을 가장 많이 적는 곳이 선언문인 만큼, 선언문의 구조만 봐도 C의 타입 시스템이 어떻게 돌아가는지 어느 정도 이해할 수 있습니다. 사실 선언문이 아닐 것 같은데 의외로 똑같은 규칙을 따르는 선언문인 경우도 꽤 많습니다.
기본적인 선언문의 구조는 다음과 같습니다. 초기화 구문은 생각하지 않겠습니다.
<specifiers> <declarator>;선언문은 <specifiers>와 <declarator>의 두 부분으로 나눌 수 있는데, <specifiers>는 선언할 것의 기초적인 타입 등의 정보를 나타내고 1개 이상을 띄어쓰기로 구분해서 작성하는 한편, <declarator>는 선언할 것의 이름과 추가 정보를 나타내고 0개 이상을 반점으로 구분해서 작성합니다. <specifiers>는 그 뒤에 따라붙는 모든 <declarator>에 동일하게 적용됩니다.
1번 떡밥을 회수하겠다고 약속했으니 우선 간단한 실험을 해봅시다. 포인터 표기(*)는 <specifiers>에 속할까요, <declarator>에 속할까요? 아래와 같은 코드를 작성해보면 바로 알 수 있습니다.
// 실제 출력값은 구현체에 따라 바뀔 수 있습니다.
// 64비트 기기에서는 웬만하면 아래와 같이 출력됩니다.
char* a, b;
printf("%d %d", sizeof a, sizeof b); // 8 1a와 b의 크기가 다르네요! 크기가 다르다는 것은 곧 다른 타입이라는 의미입니다. *가 <specifiers>에 속했다면 이런 동작을 보일 이유가 없으므로 *는 <declarator>에 속한다는 것을 알 수 있습니다. 더 구체적으로는 <specifiers>는 char, <declarator>는 * a 한 묶음, b 한 묶음으로 해석되었습니다. 이런 동작의 연장선에서 int* x;보다 int *x;가 실제 언어의 동작에 더 가까우므로 더욱 올바르다는 주장을 할 수 있겠습니다.
사실 위에서는 언어가 '어떻게' 동작하는지만 보였지 '왜'에 대한 언급은 하지 않았는데, 글의 구성상 여기 말고 아래의 #<declarator>가 그렇게 구현된 이유에서 살펴보겠습니다. 궁금하시다면 해당 부분을 먼저 읽고 오셔도 됩니다.
<specifiers> 자세히 살펴보기
<specifiers>에는 다음과 같은 것들이 임의의 순서대로 올 수 있습니다.
- 기본적인 타입을 나타내는 타입 지정자 (1개)
- 개체를 메모리상에 어떻게, 언제까지 기록할지 결정하는 기억 부류 지정자 (1개 이하)
- 개체의 성질을 나타내는 한정자 (0개 이상)
- (함수를 선언할 경우) 함수의 성질을 나타내는 함수 지정자 (0개 이상)
- C11 메모리상의 정렬 규칙을 나타내는
_Alignas(0개 이상. 이 글에서는 다루지 않습니다.)- C23 이전에는
<stdalign.h>에서_Alignas에 해당하는 매크로alignas를 제공했습니다. C23부터는 이 키워드의 이름이alignas로 바뀌었고_Alignas는 비권장*deprecated 동의어가 되었습니다.
- C23 이전에는
이때 "임의의 순서대로"라는 것은 단어 단위이기 때문에 서로 다른 종류의 키워드를 아무 순서대로 섞어 쓸 수 있습니다. 예를 들어 아래에서 등호 양쪽의 코드는 모두 같은 의미입니다. 가독성을 위해 웬만하면 이러지 말고 순서를 정해서 작성해 주세요.
signed char=char signedlong long=signed long long int=int long signed long- 위의 경우
signed와int는 생략 가능합니다.
- 위의 경우
static volatile long double _Complex=_Complex long volatile static double- 부연 설명: 타입 지정자는
long double _Complex, 기억 부류 지정자는static, 한정자는volatile입니다.
- 부연 설명: 타입 지정자는
타입 지정자type specifiers
타입 지정자는 선언되는 것의 기본적인 타입 정보를 나타냅니다. 단, 타입 지정자만으로 모든 의미가 결정되는 것은 아니고 다른 지정자나 파생 타입 표기 등으로 추가적인 의미를 더할 수 있습니다. 여기에 올 수 있는 것들은 크게 네 가지, 조금 더 작게는 여섯 가지로 분류할 수 있습니다.
기본 타입
여기서 기본 타입이란 표준·사용자 라이브러리나 매크로 등에서 제공하지 않는, 언어 자체에서 제공하는 타입을 의미합니다. 현재 C에서 제공하는 기본 타입은 다음과 같습니다.
주의
아래의 분류는 표준에서 정의하는 것과 다르며, 키워드 조합의 직교성을 기준으로 삼았습니다.
void- C99 부울:
_Bool(C23bool)- C23 이전에는
<stdbool.h>에서_Bool에 해당하는 매크로bool을 제공했습니다. C23부터는 이 타입의 이름이bool로 바뀌었고_Bool은 비권장 동의어가 되었습니다. 이 글에서는 통일성을 위해_Bool로 작성합니다.
- C23 이전에는
- 문자:
char- 부호: (없음) (기본값),
signed,unsigned
- 부호: (없음) (기본값),
- 정수:
int- 부호:
signed(기본값),unsigned - 크기:
short, (없음) (기본값),long, C99long long - 부호나 크기 키워드가 있을 경우
int키워드는 생략할 수 있습니다. - C99
int계열 타입 이외에도 구현체에서 정의하는 확장 정수 타입이 제공될 수 있습니다.
- 부호:
- C23 비트 정수:
_BitInt(n)- 부호:
signed(기본값),unsigned - 부호 비트를 포함해 정확히 n비트를 차지하는 정수 타입을 나타냅니다. n은
<limits.h>에서 정의하는BITINT_MAXWIDTH보다 클 수 없습니다.
- 부호:
- 이진 부동소숫점:
float,double,long double- C99 복소수 여부: (없음) (기본값),
_Imaginary,_Complex<complex.h>에서_Imaginary와_Complex에 해당하는 매크로imaginary와complex를 제공합니다.
- C99 복소수 여부: (없음) (기본값),
- C23 십진 부동소숫점:
_Decimal32,_Decimal64,_Decimal128- 이진법을 기반으로 하는 기존의 부동소숫점 타입과 다르게 십진법을 기반으로 합니다.
- C23 널 포인터:
nullptr_tnullptr가 가지는 타입입니다. 엄밀히 말해 이 타입은typedef typeof(nullptr) nullptr_t;로 정의되지만, C23 이전의NULL과 달리 그 자체로는 포인터가 아닌 별개의 타입이고 달리 이 타입을 가리키는 방법이 없으므로 기본 타입으로 간주하고 여기에 작성합니다.
주의
-
위에 나열된 타입 중 구현체에서 복소수와 십진 부동소숫점을 구현하지 않거나, 이진 부동소숫점을 (이하 '부동소숫점 표준')에 어긋나게 구현할 수 있습니다. 각각의 구현 여부는 다음 매크로 상수로 확인할 수 있습니다.
- 이진 부동소숫점 (부록 F)
__STDC_IEC_559__(C23부터 비권장): 부동소숫점 표준을 만족할 경우1로 정의됩니다.- C23
__STDC_IEC_60559_BFP__: 부동소숫점 표준을 만족할 경우202311L로 정의됩니다.
- 복소수 (부록 G)
__STDC_IEC_559_COMPLEX__(C23부터 비권장): 지원할 경우1로 정의됩니다.- C11 이전까지는 이 매크로 상수가 있어도 순허수를 지원하지 않을 수 있었습니다. C11부터는 순허수를 반드시 지원하도록 변경되었습니다.
- C23
__STDC_IEC_60559_COMPLEX__: 지원할 경우202311L로 정의됩니다. __STDC_NO_COMPLEX__: 복소수나<complex.h>를 지원하지 않을 경우1로 정의됩니다.
- 십진 부동소숫점 (부록 F 일부)
__STDC_IEC_60559_DFP__: 지원할 경우202311L로 정의됩니다.
- 이진 부동소숫점 (부록 F)
-
char는signed char나unsigned char와 같은 타입이 아닌 별개의 타입입니다. 더 자세히는,char는signed char혹은unsigned char중 하나와 같은 동작을 하지만 어느 것을 택할지는 구현체에서 정의합니다.char와signed char,unsigned char를 문자 타입으로 통칭한다. 구현체는char의 범위와 표현, 동작이signed char혹은unsigned char중 하나와 일치하도록 정의하여야 한다. -
정수 타입의 크기도 구현체에서 정의합니다. 표준에서 추가적인 제한을 두고 있는데, 결과적으로 다음이 성립합니다.
-
char는 8비트 이상 -
short와int는 16비트 이상 -
long은 32비트 이상 -
long long은 64비트 이상 -
1 =
sizeof(char)≤sizeof(short)≤sizeof(int)≤sizeof(long)≤sizeof(long long) -
재미있는 사실! 1바이트가 몇 비트인지도 구현체에서 정의합니다. 과거에는 컴퓨터마다 1바이트를 1비트부터 48비트까지 다양한 값으로 정했다고 하는데, 현대의 범용 컴퓨터는 사실상 8비트 바이트로 통일되었으므로 특정 분야가 아니면 큰 의미가 없습니다.3
용어 관련 참고 2: 바이트는 연속된 비트의 열로 이루어지며, 그 개수는 구현체에서 정의한다.
-
표준에서의 타입 분류
표준에서는 추가로 특정한 타입을 통칭하는 용어를 몇 가지 정의하고 있습니다.
- 개체 타입object types: 함수 타입이 아닌 모든 타입
- 문자 타입character types: 위에서 문자로 분류한 타입
- 정수 타입integer types:
char, 위에서 정수나 비트 정수로 분류한 타입, 열거형 - 실수 타입real types: 정수 타입, 위에서 이진 부동소숫점이나 C23 십진 부동소숫점으로 분류한 타입 중 C99
_Imaginary나_Complex가 아닌 것 - 산술 타입arithmetic types: 정수 타입, 위에서 이진 부동소숫점이나 C23 십진 부동소숫점으로 분류한 타입
- 스칼라 타입scalar types: 산술 타입, 포인터 타입, C23
nullptr_t - 집합 타입*aggregate types: 배열 타입, 구조체 타입
- 파생 선언자 타입*derived declarator types: 배열 타입, 함수 타입, 포인터 타입
- 파생 선언자 타입은 아래의 #
<declarator>자세히 살펴보기에서 언급할 세 가지 파생 타입과 일치합니다. '파생 선언자'라는 이름도 여기에서 온 듯합니다.
- 파생 선언자 타입은 아래의 #
주의
사용자 정의 타입과 주의사항
아래의 구조체, 공용체, 열거형은 모두 기존의 타입과 다른 새로운 타입을 정의하고, 그 타입에 태그(struct/union/enum 바로 다음에 오는 식별자)를 붙일 수 있다는 점에서 비슷하며, 이 이유로 이 글에서는 '사용자 정의 타입'으로 따로 분류합니다. 사용자 정의 타입을 설명하기 전에 공통되는 사용 방법과 주의사항을 여기에 작성합니다.
새로운 타입은 다음과 같은 세 가지 방식으로 정의할 수 있습니다.
-
태그만 작성하면 새로운 타입을 선언만 하거나, 이미 정의한 타입의 변수를 선언할 수도 있습니다. 일단 선언하고 나면 그 타입의 정의는 실제로 변수를 선언하기 전까지만 작성하면 됩니다.
- 정의하지 않은 타입은 불완전 타입으로 취급되어 변수를 선언하는 데 사용할 수 없습니다.
// ✅ `struct Foo`가 정의 없이 선언되었습니다. struct Foo; // ❌ 아직 정의하지 않은 `struct Foo` 타입의 변수를 선언할 수 없습니다. struct Foo x; // ✅ 기존에 선언했던 `struct Foo`가 정의되었습니다. struct Foo { int foo; }; // ✅ `struct Foo` 타입의 변수가 선언되었습니다. struct Foo x; -
태그 없이 정의만 작성하면 일회용 익명 타입을 정의할 수 있습니다. 나중에 이 타입을 참조하려면 C23
typeof를 사용해야 합니다. 이렇게 정의한 익명 타입끼리는 정의가 완전히 같더라도 다른 타입이므로 서로 대입할 수 없습니다.// ✅ 익명의 구조체 (a)와 그 타입의 변수 `a`와 `b`가 선언되었습니다. struct /* (a) */ { int x; } a = { 1 }, b; // ✅ `a`를 같은 타입인 `b`에 대입할 수 있습니다. b = a; // ✅ 익명의 구조체 (b)와 그 타입의 변수 `c`가 선언되었습니다. // (a)와 (b)는 다른 타입입니다. struct /* (b) */ { int x; } c; // ❌ 구조체 (a) 타입을 가지는 `a`를 구조체 (b) 타입을 가지는 `c`에 대입할 수 없습니다. c = a; -
태그와 정의를 모두 작성하면 새로운 타입을 선언하는 동시에 정의하거나, 이미 선언한 타입이라면 정의를 추가할 수 있습니다. 각 타입은 한 번만 정의할 수 있습니다.
// ✅ `struct Foo`가 선언과 동시에 정의되었습니다. struct Foo { int x; }; // ❌ 이미 정의한 `struct Foo`를 재정의할 수 없습니다. struct Foo { int x; }; -
참고로 태그와 정의를 모두 생략할 수는 없습니다.
// ❌ 의미 없는 선언문 struct;
일단 선언하고 나면 태그 타입을 포함해 다음과 같은 형태로 쓸 수 있습니다.
- 구조체:
struct Foo(Foo가 아닙니다!) - 공용체:
union Foo - 열거형:
enum Foo
태그 타입 없이 태그만 단독으로 사용할 수는 없지만, typedef를 통해 동의어를 만들어서 쓸 수 있습니다.
struct Foo {
int x;
};
// ✅ `Foo`가 `struct Foo`의 동의어로 선언되었습니다.
typedef struct Foo Foo;
// ✅ `Foo` (aka `struct Foo`) 타입의 변수가 선언되었습니다.
Foo foo;
// ✅ `Bar`가 익명 구조체 (a)의 동의어로 선언되었습니다.
typedef struct /* (a) */ {
int x;
} Bar;
// ✅ `Bar` (aka 구조체 (a)) 타입의 변수가 선언되었습니다.
Bar bar;의외로 태그 이름이 같은 구조체와 공용체, 열거형은 동시에 선언할 수 없습니다.
// ✅ `struct Foo`가 선언되었습니다.
struct Foo;
// ❌ 태그 이름 `Foo`가 중복됩니다.
union Foo;
// ❌ 태그 이름 `Foo`가 중복됩니다.
enum Foo;타입 선언도 변수처럼 블록 범위를 가지며, 블록 안에서 블록 밖에 있는 같은 이름의 타입을 가릴 수 있습니다.
// ✅ `struct Foo` (a)가 선언되었습니다.
struct Foo /* (a) */ {
int x;
};
// ✅ `struct Foo` (a) 타입의 변수 `outer`가 정의되었습니다.
struct Foo outer = { 1 };
void fn(void) {
// ✅ `struct Foo` (b)가 선언과 동시에 정의되었습니다.
// 이 타입은 `fn`의 본문 안에서 `struct Foo` (a)를 가리며,
// `fn` 밖에서는 `struct Foo` (a)를 계속 사용할 수 있습니다.
struct Foo /* (b) */ {
int x;
};
// ✅ `struct Foo` (b) 타입의 변수 `inner`가 정의되었습니다.
struct Foo inner = { 1 };
// ❌ `struct Foo` (a) 타입을 가지는 `outer`를 `struct Foo` (b) 타입을 가지는 `inner`에 대입할 수 없습니다.
inner = outer;
}
void fn2(void) {
// ✅ 가려지지 않은 `struct Foo` (a) 타입의 변수가 정의되었습니다.
struct Foo inner = outer;
}
void fn3(void) {
// ✅ `struct Foo` (c)가 선언되었습니다.
// `fn` 안에서처럼 구조체를 완전히 정의하지 않아도 선언만으로 `struct Foo` (a)가 가려집니다.
struct Foo /* (c) */;
// ❌ `struct Foo` (c)가 선언은 되었지만 정의되지 않았으므로 그 타입의 변수를 선언할 수 없습니다.
struct Foo x;
}구조체
구조체의 '풀 네임'이 structure라는 것을 알고 계셨나요? 저는 C를 시작한 이후로 구조체를 항상 struct로만 접해 와서 오히려 structure가 더 어색하게 느껴집니다.
구조체는 하나 이상의 값을 멤버로 가지는 값으로, 멤버들은 각자의 메모리 공간이 있어서 서로를 침범하지 않습니다.
빈 구조체(엄밀히는 기명named 멤버가 없는 구조체)를 정의하려고 하면 비정의 동작이 됩니다. GCC 등 일부 컴파일러에서는 언어 확장으로 빈 구조체를 지원하기도 합니다.
// 🔥 UB: 구조체에 기명 멤버가 없습니다.
struct Empty {};비트필드bit-fields
참고
여기서는 설명의 편의를 위해 int가 32비트를 차지하고 2의 보수 표현을 사용하는 것으로 가정합니다.
더 알아보기
표준에서 허용하는 부호 있는 정수 표현
표준에서는 부호 있는 정수를 다음 셋 중 하나의 방법으로 표현하도록 규정하고 있습니다. 세 방법 모두 부호 비트가 0이면 그 비트를 무시하고 이진법으로 읽습니다.
- 부호와 절댓값sign and magnitude 표현: 음의 부호를 붙이는 연산이 부호 비트를 반전하는 연산에 대응합니다.
- 1의 보수one's complement 표현: 음의 부호를 붙이는 연산이 모든 비트를 반전하는 연산에 대응합니다.
- 2의 보수two's complement 표현: 음의 부호를 붙이는 연산이 모든 비트를 반전하고 1을 더하는 연산에 대응합니다.
위 세 방식 중 2의 보수 표현이 표현 범위가 더 넓고 부호 없는 덧셈·뺄셈·곱셈 연산을 그대로 사용할 수 있다는 장점을 가지며, 대부분의 컴퓨터에서 채택되고 있습니다.
C23부터는 표준에서 부호와 절댓값, 1의 보수 표현이 폐지되고 모든 부호 있는 정수가 2의 보수로 표현됩니다.
구조체 안의 메모리 영역을 비트 단위로 지정해 사용할 수 있고, 구조체 멤버 바로 다음에 콜론(:)과 비트 수를 적으면 됩니다. 비트 수는 기반으로 하는 타입의 크기보다 클 수 없습니다.
struct Foo {
// ✅ 3비트를 차지하는 부호 없는 비트필드 멤버 `a`가 선언되었습니다.
// `a`의 범위는 0 이상 7 이하입니다.
unsigned int a: 3;
// ✅ 4비트를 차지하는 부호 있는 비트필드 멤버 `b`가 선언되었습니다.
// `b`의 범위는 -8 이상 7 이하입니다.
signed int b: 4;
};비트필드의 기반 타입으로 사용할 수 있는 타입은 다음과 같습니다.
-
unsigned int: 부호 없는 정수 멤버로 사용할 수 있습니다. n비트짜리 비트필드의 범위는 0 이상미만입니다. -
signed int: 부호 있는 정수 멤버로 사용할 수 있습니다. n비트짜리 비트필드의 범위는이상 미만입니다. -
int: 원래int는signed int와 같은 의미이지만, 비트필드로 사용할 때는char와 비슷한 의미를 가집니다. 즉,signed int나unsigned int중 하나와 같은 동작을 하지만 어느 것을 택할지는 구현체에서 정의합니다.[6.7.3.1/2의 목록에서] 반점으로 구분된 각 중복집합의 모든 원소는 같은 타입을 나타내지만, 예외적으로 비트필드의 경우 지정자
int가signed int와 같은 타입을 나타낼지unsigned int와 같은 타입을 나타낼지는 구현체에서 정의한다. -
C99
_Bool: 1비트 비트필드로 사용할 경우 0 이상 1 이하의 범위를 가지고_Bool과 같은 의미를 가집니다. 이 타입은 논리적으로 1비트의 너비를 가지므로 2비트 이상의 비트필드로 사용할 수는 없습니다. -
C23
_BitInt(n)과unsigned _BitInt(n): 각각signed int와unsigned int와 비슷한 의미를 가집니다. -
이외 구현체에서 정의하는 타입
-
const/volatile한정을 지원합니다. -
C11
_Atomic타입의 지원 여부는 구현체에서 정의합니다.
비트필드가 연속될 경우 공간이 남으면 반드시 연속된 비트를 사용합니다. 공간이 남지 않을 때 다음 개체로 넘어갈지 여러 개체에 걸칠지는 구현체에서 정의합니다.
멤버 이름을 생략한 비트필드도 만들 수 있습니다.
struct Foo {
// ✅ 기명 비트필드 멤버 `a`와 `b`, 무기명 비트필드 멤버 1개가 선언되었습니다.
// `a`와 `b`는 메모리상에서 4비트 떨어져 있습니다.
unsigned int
a: 3,
: 4,
b: 5;
};무기명 비트필드의 경우 0비트짜리의 특수한 비트필드가 허용되는데, 다음 비트필드를 같은 개체에 연속으로 할당하지 않고 다음 개체로 넘기는 역할을 합니다.
struct Foo {
// ✅ 기명 비트필드 멤버 `a`와 `b`가 선언되었습니다.
// `a`와 `b`는 메모리상에서 서로 다른 `unsigned int` 개체에 속하며, 29비트 떨어져 있습니다.
unsigned int
a: 3,
: 0,
b: 5;
};C99 유연 배열 멤버*flexible array members
구조체에 기명 멤버가 있을 경우 맨 마지막에 불완전 배열 멤버를 하나 더 선언할 수 있고, 이 멤버를 유연 배열 멤버라고 합니다.
이 멤버는 그 자체로 구조체에 포함되지는 않지만(초기화할 수도 없고, 대입 연산이나 sizeof에서도 제외됩니다), 의도적으로 구조체의 크기보다 큰 메모리를 할당하고 남는 부분에 접근하는 데 사용할 수 있습니다. 단, 실제로 할당된 메모리 밖을 참조할 수는 없습니다.
struct Foo {
int a;
// ✅ `b`가 유연 배열 멤버로 선언되었습니다.
long long b[];
};
// ✅ `struct Foo` 타입의 `foo`가 정의되었습니다.
struct Foo foo = { 1 };
// 🔥 UB: 추가로 할당된 공간이 없으므로 유연 배열 멤버를 사용할 수 없습니다.
foo.b[0] = 1;
// ✅ 공간이 할당되지 않았지만 포인터는 만들 수 있습니다.
// 이 너머의 포인터를 만드는 것은 UB입니다.
long long *ptr = &foo.b[0];
// ❌ 유연 배열 멤버를 초기화할 수 없습니다.
struct Foo foo2 = { 1, { 2 } };
// ✅ `struct Foo` + `long long` 2개 + 1바이트 크기의 공간이 할당되었습니다.
// 유연 배열 멤버 `bar->b`는 `long long [2]`처럼 사용할 수 있습니다.
struct Foo *bar = malloc(sizeof(struct Foo) + 2*sizeof(long long) + 1);
bar->a = 0;
// ✅ `*bar`의 유연 배열 멤버에 접근했습니다.
bar->b[1] = 2;
// 🔥 UB: 남는 1바이트는 `long long`의 크기보다 작으므로 접근할 수 없습니다.
bar->b[2] = 3;유연 배열 멤버는 추가로 할당된 공간이 없더라도 길이가 1인 배열처럼 동작합니다. 단, 배열의 원소에 실제로 접근할 수는 없습니다.
C11 익명 구조체anonymous structs
무기명 구조체를 구조체나 공용체의 멤버로 선언할 수 있고, 이 멤버를 익명 구조체라고 합니다.
안긴 익명 구조체의 멤버는 안은 구조체나 공용체에 직접 속하는 멤버처럼 사용할 수 있으며, 익명 구조체를 재귀적으로 사용할 수도 있습니다.
struct Foo {
// ✅ `a`가 `struct Foo`의 멤버로 선언되었습니다.
int a;
// ✅ 익명 구조체 멤버 (a)가 `struct Foo`의 멤버로 선언되었습니다.
struct {
// ✅ `b`가 익명 구조체 (a)의 멤버로 선언되었습니다.
// `b`는 `struct Foo`의 멤버처럼 사용할 수 있습니다.
int b;
// ✅ 익명 구조체 멤버 (b)가 익명 구조체 (a)의 멤버로 선언되었습니다.
struct {
// ✅ `c`가 익명 구조체 (b)의 멤버로 선언되었습니다.
// `c`는 `struct Foo`의 멤버처럼 사용할 수 있습니다.
int c;
} /* (b) */;
} /* (a) */;
struct {
// ✅ `d`가 `e`의 멤버로 선언되었습니다.
// `e`는 익명 구조체 멤버가 아니므로
// `d`를 `struct Foo`의 멤버처럼 사용할 수 없습니다.
int d;
} e;
};
struct Foo foo;
// ✅ `struct Foo`의 멤버
// `a`에 접근했습니다.
foo.a = 1;
// ✅ `struct Foo`의 멤버인
// 익명 구조체 (a)의 멤버
// `b`에 접근했습니다.
foo.b = 1;
// ✅ `struct Foo`의 멤버인
// 익명 구조체 (a)의 멤버인
// 익명 구조체 (b)의 멤버
// `c`에 접근했습니다.
foo.c = 1;
// ❌ `e`는 익명 구조체 멤버가 아니므로 `e`의 멤버인 `d`에 직접 접근할 수 없습니다.
foo.d = 1;공용체
공용체는 구조체처럼 하나 이상의 값을 멤버로 가지지만, 모든 멤버가 같은 메모리 공간을 공유하기 때문에 한 멤버에 쓰면 다른 멤버가 덮어쓰입니다. 구조체만큼 자주 쓰이지는 않지만, 합 타입sum types을 모사하거나 C99 타입 퍼닝type punning 등 저수준 조작을 하는 등의 용도로 사용할 수 있습니다.
구조체와 같이 빈 공용체(엄밀히는 기명named 멤버가 없는 공용체)를 정의하려고 하면 비정의 동작이 됩니다. GCC 등 일부 컴파일러에서는 언어 확장으로 빈 공용체를 지원하기도 합니다.
// 🔥 UB: 공용체에 기명 멤버가 없습니다.
union Empty {};비트필드bit-fields
구조체와 같이 비트필드 멤버를 선언할 수 있으며, 모든 비트필드가 같은 메모리 공간을 공유합니다. 이때 무기명 : 0 비트필드는 의미가 없습니다.
C11 익명 공용체anonymous unions
구조체와 같이 무기명 공용체도 구조체나 공용체의 멤버로 선언할 수 있고, 이 멤버를 익명 공용체라고 합니다.
익명 구조체와 익명 공용체는 같은 방법으로 사용할 수 있고, 서로 혼용할 수도 있습니다.
열거형
열거형은 하나 이상의 열거형 상수를 거느리는 타입입니다.
열거형은 타입 시스템상으로는 다른 어떤 타입과도 다른 새로운 타입이지만, 내부적으로는 열거형마다 기반으로 하는 타입이 있어 그 타입처럼 동작합니다. 열거형의 기반이 될 수 있는 타입은 모든 멤버의 값을 표현할 수 있는 다음 타입 중 구현체가 정의하는 것으로 합니다.
char- 이 글에서 정수로 분류한 타입
열거형의 첫 멤버의 값은 0이며, 나머지 멤버는 따로 정하지 않을 경우 이전 멤버에 1을 더한 값을 가집니다. 멤버 이름 바로 다음에 등호(=)와 원하는 값을 적어서 멤버의 값을 직접 설정할 수 있으며, 이 과정에서 값이 중복되어도 상관 없습니다.
enum Foo {
// ✅ `A`의 값이 0으로 정의되었습니다.
A,
// ✅ `B`의 값이 A + 1 = 1로 정의되었습니다.
B,
// ✅ `C`의 값이 5로 정의되었습니다.
C = 5,
// ✅ `D`의 값이 C + 1 = 6으로 정의되었습니다.
D,
// ✅ `E`의 값이 0으로 정의되었습니다.
// `A`와 중복되는 값을 가지지만 의미상의 문제는 없습니다.
E = 0
};C23 고정 기반 타입*fixed underlying type
사용자가 열거형의 기반 타입을 직접 설정할 수 있습니다.
// ✅ `char`를 기반 타입으로 가지는 `enum Foo`가 정의되었습니다.
enum Foo: char {
// ✅ `A`의 값이 문자 'A'로 정의되었습니다.
A = 'A'
};참고
C23에 고정 기반 타입이 추가되면서 기반 타입*underlying type과 열거 멤버 타입*enumeration member type이 명문화되는 등 타입 시스템이 많이 복잡해졌습니다. 아직 글쓴이의 이해도가 높지 않아 해당 내용은 이 글에서 다루지 않습니다.
typedef 타입 동의어
참고
여기서 2번 떡밥을 회수합니다.
typedef를 자유자재로 사용할 수 있다.
위에서 "사실 선언문이 아닐 것 같은데 의외로 똑같은 규칙을 따르는 선언문인 경우도 꽤 많"다고 했던가요? 혹시 typedef 선언도 똑같은 규칙을 따르는 선언문이라는 걸 알고 계셨나요?
일반적인 변수 선언문에 typedef만 추가하면 변수 대신 타입 동의어를 선언하는 선언문이 되며, 파생 선언자도 그대로 사용할 수 있습니다.
// ✅ `struct List`의 선언 및 정의와 동시에 두 개의 타입 동의어가 선언되었습니다.
// `ListNode`는 `struct List`의 동의어입니다.
// `ListPtr`는 `struct List *`, 즉 `struct List`의 포인터의 동의어입니다.
typedef struct List {
int value;
struct List *next;
} ListNode, *ListPtr;typedef로 함수 타입의 동의어도 선언할 수 있고, 이렇게 선언한 타입으로 함수 원형을 선언할 수도 있습니다. 단, 함수 정의에는 사용할 수 없습니다.
// ✅ `IntFn`이 `int (int)`의 동의어로 선언되었습니다.
typedef int IntFn(int);
// ✅ `IntFn foo` (aka `int foo(int)`)가 선언되었습니다.
IntFn foo;
// ✅ 기존에 선언했던 `foo`가 정의되었습니다.
int foo(int x) {
return x;
}
// ❌ `int (int)`로 선언된 `foo`를 `int (long)` 타입으로 정의할 수 없습니다.
int foo(long x) {
return x;
}
// ❌ 함수 괄호 없이 함수 본문을 정의할 수 없습니다.
IntFn foo {
return 0;
}이런 동작이 가능한 이유는 typedef가 이론상으로는 기억 부류 지정자이기 때문입니다. 기억 부류 지정자도 <specifiers>이기 때문에 순서와 상관 없이 쓸 수 있지만, 아까 말했듯이 이렇게 하지는 말아주세요.
// ✅👎 `Foo`가 `long`의 동의어로 선언되었습니다.
int typedef long Foo;C23 typeof()
typeof() 연산자를 통해 다른 식에서 타입을 가져와 <specifiers>로 사용할 수 있습니다.
// ✅ 익명의 구조체 (a)와 그 타입을 가지는 변수 `foo`가 선언되었습니다.
// 구조체 (a) 타입은 `typeof()` 이외의 방법으로는 더 이상 가리킬 수 없습니다.
struct /* (a) */ {
int foo;
} foo = { 1 };
// ✅ `typeof(foo)` (aka 구조체 (a)) 타입의 변수 `bar`가 선언되었습니다.
typeof(foo) bar = foo;typeof_unqual()은 식에서 원자성과 한정자가 제거된 타입을 가져옵니다[한정자qualifier를 제거하기 때문에 unqual(ified)입니다].
typeof()와 typeof_unqual()로 어떤 식의 타입이든 구할 수 있지만, 예외적으로 비트필드의 타입은 구할 수 없습니다.
기억 부류 지정자*storage class specifiers
C에는 다음과 같이 좁게는 다섯 개, 넓게는 일곱 개의 기억 부류 지정자가 정의되어 있습니다. 지정자마다 서로 다른 기억 기간과 연결성이 부여되어 있는데, 자세한 설명은 해당 단락에서 확인할 수 있습니다.
auto: 자동 기억 기간, 연결성 없음- C23 타입 지정자 없이 단독으로 사용하면 타입이 추론됩니다. 함수의 타입을 추론할 수는 없습니다.
register: 자동 기억 기간, 연결성 없음auto와 비슷하지만 해당 개체를 CPU 레지스터로 저장하는 것이 좋다는 최적화 힌트를 남깁니다(실제로 이런 최적화가 일어난다는 보장은 없습니다).register의 의미를 보장하기 위해register개체의 주소는 획득할 수 없다는 제한이 추가됩니다.- 현대의 컴파일러는 알아서 최적화를 잘 하기 때문에 웬만하면
register를 신경쓰지 않아도 됩니다. 실제로 C++에서는register가 C++11부터 비권장, C++17부터 폐지되었습니다.
static: 정적 기억 기간, (파일 범위일 경우) 내부 연결성extern: 정적 기억 기간, (이미 내부 연결성으로 선언된 것을 재선언하지 않는 경우) 외부 연결성- C11
_Thread_local: 스레드 기억 기간static _Thread_local: 내부 연결성extern _Thread_local: 외부 연결성- 개체 선언문에 사용할 경우 같은 개체를 선언할 때마다
_Thread_local로 선언해야 합니다. - 블록 범위의 선언문에서는 반드시 연결성을 지정해야 합니다.
- C23 이전에는
<threads.h>에서_Thread_local에 해당하는 매크로thread_local을 제공했습니다. C23부터는 이 키워드의 이름이thread_local로 바뀌었고_Thread_local은 비권장 동의어가 되었습니다.
- '유사' 기억 부류 지정자: 이론상 기억 부류 지정자로 분류되어 있지만, 실제로는 기억 부류와 무관한 동작을 합니다.
typedef- C23
constexpr: 컴파일 타임 상수를 선언합니다. 일반적인 개체처럼 주소도 획득할 수 있지만const에 준하는 의미를 가지므로 수정은 할 수 없습니다.
함수나 개체의 종류별로 사용할 수 있는 기억 부류 지정자는 다음과 같습니다.
- 파일 범위의 함수:
extern(기본값),static - 블록 범위의 함수:
extern(기본값) - 파일 범위의 개체:
extern(기본값),static,_Thread_local - 블록 범위의 개체:
auto(기본값),register,static,extern,_Thread_local - 매개변수: (없음) (기본값),
register- 기본값은
auto에 해당합니다. 명시적으로auto로 지정할 수는 없습니다.
- 기본값은
기억 기간*storage duration
기억 기간은 개체가 언제 할당되고 해제되는지를 나타내는 개념으로, 다음과 같이 네 종류가 있습니다.
- 자동automatic: 해당 개체가 선언되어 있는 블록에 들어가는 순간 할당되고, 어떤 방법으로든 그 블록을 빠져나올 때 해제됩니다.
- 단, 가변 길이 배열은 선언문이 실행되는 순간 할당되고, 그 선언의 범위 밖으로 나갈 때 해제됩니다.
- 정적static: 해당 개체는 프로그램이 실행되는 순간,
main함수가 실행되기 전 단 한 번만 할당됩니다. 정적 변수가 있는 함수를 여러 번 실행해도 그 변수가 이전의 값을 그대로 유지하는 것도 정적 기억 기간을 가지기 때문입니다. - C11 스레드thread: 해당 개체는 각 스레드마다 하나씩 소유하며, 스레드가 생성되어 시작될 때마다 할당됩니다.
- 할당allocated: 해당 개체는
malloc함수를 직접 호출해서 할당받고,free함수를 직접 호출해서 해제할 수 있습니다. 기억 부류 지정자와는 관련이 없습니다.
연결성*linkage
연결성은 프로그램을 이루는 번역 단위*translation unit 안에서 어떤 식별자가 같은 개체를 가리키는지 나타내는 개념으로, 다음과 같이 세 종류가 있습니다.
-
연결성 없음no linkage: 해당 식별자는 고유한 개체를 가리키며, 다른 어떤 식별자로도 가리킬 수 없습니다.
void foo(void) { // ✅ 연결성이 없는 변수 `x` (a)가 선언되었습니다. // `x` (a)는 현재 실행되고 있는 `foo` 안에서만 가리킬 수 있으며, // `foo` 안에서는 `x` (b)를 가리킬 수 없습니다. int x /* (a) */; } void bar(void) { // ✅ 연결성이 없는 변수 `x` (b)가 선언되었습니다. // `x` (b)는 `bar` 안에서만 가리킬 수 있으며, // `bar` 안에서는 `x` (a)를 가리킬 수 없습니다. int x /* (b) */; } -
내부 연결성internal linkage: 해당 식별자는 같은 번역 단위 안에서 어디서든 가리킬 수 있습니다.
// static_1.c // ✅ 내부 연결성을 가지는 변수 `x` (a)가 선언되었습니다. // `x` (a)는 같은 번역 단위 안의 어디서든 가리킬 수 있습니다. // 단, 다른 번역 단위 안에서는 가리킬 수 없습니다. static int x /* (a) */ = 0; int foo1(void) { // ✅ `x` (a)를 참조할 수 있습니다. // `x` (b)는 다른 번역 단위에서 선언했으므로 참조할 수 없습니다. return x++; } void run1(void) { printf("%d\n", foo1()); // 0 printf("%d\n", foo1()); // 1 printf("%d\n", foo1()); // 2 }// static_2.c // ✅ 내부 연결성을 가지는 변수 `x` (b)가 선언되었습니다. // `x` (b)는 같은 번역 단위 안의 어디서든 가리킬 수 있습니다. // 단, 다른 번역 단위 안에서는 가리킬 수 없습니다. static int x /* (b) */ = 100; int foo2(void) { // ✅ `x` (b)를 참조할 수 있습니다. // `x` (a)는 다른 번역 단위에서 선언했으므로 참조할 수 없습니다. return x++; } void run2(void) { printf("%d\n", foo2()); // 100 printf("%d\n", foo2()); // 101 printf("%d\n", foo2()); // 102 } -
외부 연결성external linkage: 해당 식별자는 같은 프로그램 안에서 어디서든 가리킬 수 있습니다.
// extern_1.c // ✅ 외부 연결성을 가지는 변수 `x`가 선언과 동시에 정의되었습니다. // `x`는 이 번역 단위를 포함해 같은 프로그램 안의 어디서든 가리킬 수 있습니다. // 여기에 작성한 `extern`은 생략할 수 있습니다. extern int x = 0; int foo1(void) { // ✅ `x`를 참조할 수 있습니다. return x++; } void run1(void) { printf("%d\n", foo1()); printf("%d\n", foo1()); printf("%d\n", foo1()); }// extern_2.c // ✅ 외부 연결성을 가지는 변수 `x`가 선언되었습니다. // 이 `x`는 `extern_1.c`에서 선언하고 정의한 `x`와 같은 개체를 가리킵니다. // 여기서 `extern`을 생략하면 `x`를 **새로 정의**하고 공백 초기화하는 것이 되므로 생략할 수 없습니다. extern int x; int foo1(void); int foo2(void) { // ✅ `x`를 참조할 수 있습니다. return x++; } void run1(void); void run2(void) { printf("%d\n", foo2()); printf("%d\n", foo2()); printf("%d\n", foo2()); } int main(void) { run1(); // 0 // 1 // 2 run2(); // 3 // 4 // 5 run1(); // 6 // 7 // 8 }
한정자qualifiers
참고
여기서 3번 떡밥을 회수합니다.
const int *x;와int const *x;와int * const x;의 차이를 이해할 수 있다.
C에는 세 종류의 한정자가 있으며, 개체와 상호작용을 하는 데 제한을 두는 역할을 합니다. 이렇게 바뀐 개체의 의미는 안전성이나 컴파일러 최적화에 영향을 미칩니다.
주의
C11 _Atomic도 한정자처럼 사용할 수 있지만, 개체와의 상호작용 방식만을 제한하는 다른 세 한정자와 달리 _Atomic을 사용하면 기존의 타입이 크기나 정렬성, 표현 방식이 다를 수 있는 원자적 타입으로 변경됩니다. 제가 이해한 바로는 한정자 _Atomic은 타입 지정자 _Atomic()의 문법적 설탕에 가깝습니다.
이 글에서는 _Atomic을 다루지 않습니다.
한정자의 위치
한정자는 <specifiers> 자리와 포인터 선언자(*) 바로 뒤의 두 자리에 올 수 있습니다.
-
<specifiers>자리에 붙으면 타입 지정자가 한정됩니다.// ✅ `int`가 `const` 한정되었습니다. // `x`는 `const`가 아니지만, `*x`는 `const`입니다. const int *x; // ✅ `const int`와 `int const`는 같은 의미입니다. int const *y; -
포인터 선언자 자리에 붙으면 포인터가 한정됩니다. 여러 한정자를 동시에 사용할 수도 있으며, 매개변수 자리에 작성해서 포인터로 변환을 거치는 배열에도 사용할 수 있습니다.
// ✅ `int *`가 `const` 한정되었습니다. // `x`는 `const`이지만, `*x`는 `const`가 아닙니다. int *const x; // ✅ `int *`가 동시에 `const`, `volatile` 한정되었습니다. int *const volatile y; // ✅ 첫 번째 매개변수의 타입에서 `int [4]` (aka `int *`)가 한정되었습니다. // `foo`의 본문 안에서 `arg`는 `const`이지만, `arg[x]`는 `const`가 아닙니다. void foo(int arg[const 4]);- 개인적으로 프로그래머의 의도를 명확히 하기 위해 위에서처럼 포인터 선언자와 한정자를 붙여 쓰는 것이 좋다고 생각합니다. cppreference.com에서도 이 서식을 사용하고 있습니다.
물론 두 방식을 동시에 사용할 수도 있습니다.
const int *x:int가 한정됩니다.x는const int *이며,const가 아닙니다.*x는const int이며,const입니다.
int *const x:int *가 한정됩니다.x는int *const이며,const입니다.*x는int이며,const가 아닙니다.
const int *const x:int와int *가 동시에 한정됩니다.x는const int *const이며,const입니다.*x는const int이며,const입니다.
- 심화 예제:
const int *const *volatile x에서int와int *는const,int **는volatile한정됩니다.x는volatile이지만const는 아닙니다.*x는const이지만volatile은 아닙니다.**x는const이지만volatile은 아닙니다.
const 한정자
const 한정자는 개체에 '쓰기 연산 금지'의 의미를 더합니다. 일단 초기화가 끝난 const 개체(나 const인 멤버가 하나라도 있는 개체)에는 쓰기 연산을 할 수 없으며, 컴파일러가 이 성질을 이용해 최적화를 할 수 있습니다.
// ✅ `const` 한정된 변수가 선언되었습니다.
const int x = 5;
// ❌ `const` 한정된 개체에 쓸 수 없습니다.
x = 6;
// ✅ `const` 한정된 멤버가 있는 구조체가 선언되었습니다.
struct {
int x;
const int y;
} y = { 1, 2 }, z = { 3, 4 };
// ❌ `const` 한정된 멤버가 있으므로 쓸 수 없습니다.
y = z;volatile 한정자
volatile 한정자는 개체에 '최적화 금지'의 의미를 더합니다. volatile 한정된 개체의 읽기/쓰기 연산은 부작용side effect으로 취급되어 최적화 없이 있는 그대로 실행됩니다. 입출력 신호가 메모리 매핑이 되어 있거나, 벤치마크 등 최적화를 해서는 안 되는 상황 등에 사용합니다.
volatile의 실제 효과를 살펴보려면 컴파일을 거친 뒤 어셈블리 코드를 확인해야 합니다. Compiler Explorer에서 아래 코드를 -O2 (중간 단계의 최적화) 플래그로 컴파일하면 다음과 같은 출력을 확인할 수 있습니다.
int foo(void) {
int x = 0;
for(int i = 0; i < 100; i++)
x++;
return x;
}
int bar(void) {
volatile int x = 0;
for(int i = 0; i < 100; i++)
x++;
return x;
}foo:
mov eax, 100
ret
bar:
mov DWORD PTR [rsp-4], 0
mov edx, 100
.L4:
mov eax, DWORD PTR [rsp-4]
add eax, 1
mov DWORD PTR [rsp-4], eax
sub edx, 1
jne .L4
mov eax, DWORD PTR [rsp-4]
ret독자의 편의를 위해 도로 의사코드로 돌려놓으면 다음과 같습니다. eax, edx, rsp는 CPU 레지스터이고, 포인터 산술은 바이트 단위인 것으로 가정합니다.
int foo() {
eax = 100;
return eax;
}
int bar() {
*(rsp - 4) = 0;
edx = 100;
L4:
eax = *(rsp - 4);
eax++;
*(rsp - 4) = eax;
edx--;
if(edx != 0)
goto L4;
eax = *(rsp - 4);
return eax;
}foo는 사실상 return 100;으로 최적화된 반면, bar는 x를 0으로 초기화하는 동작, 루프 안에서 읽고 쓰는 동작, return문에서 다시 읽는 동작까지 모두 보존되어 있습니다.
restrict 한정자
주의
이 단락에는 오개념이 있을 수 있습니다. 잘못된 내용을 찾으셨다면 꼭 알려주세요.
restrict 한정자는 개체를 직접 한정할 수 없으며, 개체를 가리키는 포인터나 C23 그런 포인터를 담는 1차원 이상의 배열만을 한정할 수 있습니다.
// ✅ `int *`가 `restrict` 한정되었습니다.
int *restrict x;
// ❌ 포인터가 아닌 `int`를 직접 `restrict` 한정할 수 없습니다.
restrict int y;restrict 한정자는 개체의 포인터에 '에일리어싱aliasing 금지'의 의미를 더합니다. restrict 포인터가 있는 블록에서 그 포인터를 통해 어떤 개체에 직·간접적으로 쓰기 연산을 했다면 그 개체는 그 블록 안에서 그 포인터로만 참조할 수 있으며, 다른 경로로 참조할 경우 (컴파일러가 확인할 수 없으므로) 비정의 동작이 됩니다.
void foo(int *restrict x, int *restrict y) {
*y += *x;
*x += *y;
}
int x = 1, y = 1;
// ✅ `x`와 `y`가 올바르게 수정되었습니다.
foo(&x, &y);
// 🔥 UB: `restrict` 한정된 두 인자가 같은 개체를 가리킬 수 없습니다.
foo(&x, &x);restrict 포인터를 다른 restrict 포인터 변수에 대입하려고 하면 에일리어싱이 되므로 비정의 동작이 됩니다. 단, 다음의 두 경우는 예외입니다.
- 바깥 블록에 있는
restrict포인터를 안쪽 블록에 있는restrict포인터에 대입하는 경우- 함수 인자로
restrict포인터를 전달하는 것을 예로 들 수 있습니다.
- 함수 인자로
- 함수의 반환값으로 사용되는 등 종료되고 있는 블록 밖으로 대입하는 경우
restrict의 효과도 어셈블리 코드를 읽어야 쉽게 확인할 수 있습니다. Compiler Explorer에서 아래 코드를 -O2 (중간 단계의 최적화) 플래그로 컴파일하면 다음과 같은 출력을 확인할 수 있습니다.
void foo(int *x, int *y) {
*y += *x;
*x += *y;
}
void bar(int *restrict x, int *restrict y) {
*y += *x;
*x += *y;
}foo:
mov eax, DWORD PTR [rdi]
add eax, DWORD PTR [rsi]
mov DWORD PTR [rsi], eax
add DWORD PTR [rdi], eax
ret
bar:
mov eax, DWORD PTR [rdi]
mov edx, DWORD PTR [rsi]
add edx, eax
add eax, edx
mov DWORD PTR [rsi], edx
mov DWORD PTR [rdi], eax
ret역시 의사코드로 돌려놓으면 다음과 같습니다. eax, edx, rdi, rsi는 CPU 레지스터입니다.
void foo(rdi, rsi) {
eax = *rdi;
eax += *rsi;
*rsi = eax;
*rdi += eax;
}
void bar(rdi, rsi) {
eax = *rdi;
edx = *rsi;
edx += eax;
eax += edx;
*rsi = edx;
*rdi = eax;
}foo에서는 (x == y인 경우) *y를 수정하면 *x가 영향을 받을 수도 있지만, bar에서는 그렇지 않다는 의미가 더해졌기 때문에 컴파일러가 최적화한 명령을 출력할 수 있습니다.
얼핏 보면 bar의 명령어 수가 foo보다 오히려 많아진 것처럼 보이지만, 현대의 CPU는 여러 가지 최적화 기법으로 인해 명령어를 잘 배열하면 오히려 더 빨리 처리할 수 있으며, bar는 CPU가 더 효율적으로 실행할 수 있다고 컴파일러가 판단한 어셈블리 코드입니다.
주의
실제로 어느 쪽이 더 빨리 실행되는지는 상황에 따라 다릅니다. 실제로 제 컴퓨터에서 실행했을 때는 bar가 0.9% 정도 빨랐지만, 위 코드를 조금 수정해서 실행했을 때는 foo가 빨랐던 경우도 있습니다. 최적화를 할 때 감으로 하지 말고 무조건 실제 성능을 측정해보라는 말이 괜히 있는 게 아닙니다.
더 알아보기
restrict 포인터의 엄밀한 동작
표준에서 restrict 포인터의 엄밀한 정의를 살펴보면 다음과 같이 매우 복잡한 내용이 나옵니다. 저도 완전히 이해하지는 못했습니다.
6.7.4.2
restrict의 형식적 정의
- 타입 T의 restrict 한정된 포인터인 개체 P를 지시하는 수단을 제공하는 일반 식별자의 선언을 D라고 한다.
- D가 블록 안에 등장하고 D의 기억 부류가
extern이 아닐 경우, 그 블록을 B라고 한다. D가 함수 정의의 매개변수 선언 목록에 등장할 경우, 그 함수에 대응하는 블록을 B라고 한다. 이외의 경우에는main의 블록 (혹은 독립된 환경의 경우 프로그램 시작 시 호출되는 함수의 블록)을 B라고 한다.- 이하의 내용에서, (B 안에서 E를 실행하기 이전의 어떤 시퀀스 포인트에서) P를 P가 기존에 가리키던 배열 개체의 사본을 가리키도록 수정하면 포인터 식 E의 값이 바뀔 때, E가 개체 P에 기반한다고 정의한다.139) '기반한다'는 개념은 포인터 타입을 가지는 식에 대해서만 정의됨에 유의하라.
- B의 각 실행 내에서,
&L이 P에 기반하는 모든 좌측값을 L이라고 한다. L을 사용해 개체 X가 지시하는 값에 접근하고, X 역시 (어떤 수단으로든) 수정될 경우, 다음 요구사항이 적용된다: T는 const 한정되어서는 안 된다. X의 값에 접근하는 다른 모든 좌측값 역시 그 주소가 P에 기반하여야 한다. 본 조항에 대해 판단할 때 X를 수정하는 모든 접근은 P 역시 수정하는 것으로 취급하여야 한다. 다른 restrict 한정된 포인터 P2에 기반하며 블록 B2에 소속되는 포인터 식 E가 P에 대입되는 경우, B2의 실행이 B의 실행 이전에 시작되거나, B2의 실행이 대입 이전에 종료되어야 한다. 이상의 요구사항이 충족되지 않을 경우의 동작은 정의되지 않는다.- 여기서 B의 실행이란 프로그램의 실행 중 B에 소속되고, 스칼라 타입과 자동 기억 기간을 가지는 개체의 수명에 대응하는 부분을 말한다.
139) 즉, E가 P를 통해 간접적으로 참조되는 개체의 값이 아니라 P의 값에 직접 의존하는 경우를 말한다. 예를 들어, 식별자 p가
(int **restrict)타입을 가질 경우, 포인터 식p와p+1은 p가 지시하는 restrict 한정된 포인터 개체에 기반하지만, 포인터 식*p와p[1]은 그렇지 않다.
다른 타입과의 상호작용
(함수 매개변수를 제외하고) 배열의 한정을 나타내는 문법은 없지만, 배열 타입을 나타내는 typedef 동의어를 한정하는 것은 가능합니다. 이 경우에는 배열의 모든 원소가 한정되지만, 배열 자체는 한정되지 않습니다. C23 이후에는 배열의 한정 여부가 항상 원소의 한정 여부를 따라갑니다.
// ✅ `Arr`가 `int [8]`의 동의어로 선언되었습니다.
typedef int Arr[8];
// ✅ `const Arr` (aka `const` 한정된 `int [8]`) 타입의 변수가 선언되었습니다.
const Arr arr = { 0, 1, 2, 3, 4, 5, 6, 7 };
// ❌ `const` 한정된 배열 원소에 쓸 수 없습니다.
arr[4] = 40;한정자는 개체의 의미를 바꾸는 언어 기능이므로 함수를 한정할 수 없습니다. 위에서처럼 함수 타입의 typedef 동의어를 한정하려고 하면 const/volatile은 비정의 동작, restrict는 컴파일 오류가 발생합니다.
구조체나 공용체를 한정할 수 있으며, 그 구조체나 공용체의 모든 원소가 한정되는 효과를 가집니다.
// ✅ `foo`가 `const` 한정된 구조체 (a) 타입을 가지는 변수로 정의되었습니다.
const struct /* (a) */ {
int x;
} foo = { 1 };
// ❌ 구조체 (a)가 `const` 한정되었으므로 원소에도 쓸 수 없습니다.
foo.x = 2;한정되지 않은 타입의 포인터(T *)는 한정된 타입의 포인터(const T */volatile T */restrict T *)로 암시적 변환이 가능하고 대입 역시 가능하지만, 그 역은 한정자의 의미를 위반하므로 성립하지 않습니다. 이중 포인터 간의 암시적 변환은 불가능하며, 명시적 변환을 해야 합니다.
참고
이 규칙은 다음과 같이 이해하면 좋습니다.
- 쓰기 연산을 해도 되는 포인터(
T *)를 쓰기 연산을 하지 않는 포인터(const T *)에 대입해도 된다. - 쓰기 연산을 하면 안 되는 포인터(
const T *)를 쓰기 연산을 할 수도 있는 포인터(T *)에 대입하면 안 된다. - 최적화를 해도 되는 포인터(
T *)를 최적화를 하지 않는 포인터(volatile T *)에 대입해도 된다. - 최적화를 하면 안 되는 포인터(
volatile T *)를 최적화를 할 수도 있는 포인터(T *)에 대입하면 안 된다. - 에일리어싱을 해도 되는 포인터(
T **)를 에일리어싱을 하지 않는 포인터(T *restrict *)에 대입해도 된다. - 에일리어싱을 하면 안 되는 포인터(
T *restrict *)를 에일리어싱을 할 수도 있는 포인터(T **)에 대입하면 안 된다.
void *p1, **pp1;
// ✅ `void *`가 `const void *`로 암시적 변환되었습니다.
const void *p2 = p1;
// ❌ `const void *`를 `void *`로 암시적 변환할 수 없습니다.
void *p3 = p2;
// ❌ `void **`를 `const void **`로 암시적 변환할 수 없습니다.
const void **pp2 = pp1;명시적 포인터 변환 등을 통해 const/volatile 한정된 개체에 억지로 접근하려고 하면 당연히 비정의 동작이 됩니다. 특히 volatile은 읽기 연산도 비정의 동작입니다.
const int x = 1;
volatile int y = 2;
// 🔥 UB: `const` 한정되지 않은 포인터로 `const` 개체를 수정할 수 없습니다.
*(int *)&x = 3;
// 🔥 UB: `volatile` 한정되지 않은 포인터로 `volatile` 개체에 접근할 수 없습니다.
(void)*(int *)&y;함수 지정자*function specifiers
C에는 두 종류의 함수 지정자가 있으며, 함수의 성질을 바꾸는 역할을 합니다. 위의 한정자와 비슷하게 컴파일러 최적화에 영향을 미칩니다.
C99 inline
inline 함수 지정자는 해당 함수를 인라인inline 처리하는 것이 좋다는 최적화 힌트를 남깁니다(실제로 이런 최적화가 일어난다는 보장은 없습니다). inline의 의미를 보장하기 위해 static이 아닌(즉, extern인) inline 함수는 함수 본문 안에 const가 아닌 static 변수를 선언할 수 없으며, 파일 범위의 static 변수도 사용할 수 없다는 규칙이 추가되지만, inline 함수를 재귀적으로 호출하는 것은 금지되지 않으며, 실제로 어느 정도 최적화가 되는 경우도 있습니다.
C11 _Noreturn
주의
C23 이전에는 <stdnoreturn.h>에서 _Noreturn에 해당하는 매크로 noreturn을 제공했습니다. C23에 어트리뷰트 [[noreturn]]이 추가되면서 기존의 함수 지정자 _Noreturn은 비권장 기능이, noreturn은 비권장 매크로가 되었습니다.
_Noreturn은 함수에 '반환하지 않음'의 의미를 더합니다. _Noreturn 함수가 호출된 뒤 실제로 return하면 비정의 동작이 되며, 컴파일러가 이 성질을 이용해 이 함수 뒤에 오는 코드를 삭제하는 최적화를 할 수 있습니다.
_Noreturn 함수가 반환하는 대신 취할 수 있는 동작의 예로는 아래와 같은 것들이 있습니다.
- 무한 루프
- 재미있는 사실! C에서는 무한 루프가 관측 가능한 아무런 부작용을 일으키지 않으면 비정의 동작이 됩니다. 탈출 조건이 상수식이거나 (
for문의 경우) 생략된 경우는 예외입니다.
- 재미있는 사실! C에서는 무한 루프가 관측 가능한 아무런 부작용을 일으키지 않으면 비정의 동작이 됩니다. 탈출 조건이 상수식이거나 (
- (
main함수를 통하지 않는) 프로그램/스레드 종료abort()exit()- C99
_Exit() - C11
quick_exit() - C11
thrd_exit()
- (
return문을 통하지 않는) 함수 탈출longjmp()
더 알아보기
다른 언어에서 '반환값 없음'과 '반환하지 않음'의 구분
void가 함수의 반환 타입에서 특별한 의미를 가지는 C나 Java 등의 주류 언어와 달리, Haskell이나 Rust 등 타입 시스템이 발달한 일부 언어에서는 하나의 값이 속하는 '단위 타입unit type'과 아무런 값도 속하지 않는 '바닥 타입bottom type'을 구분해 더욱 일관적으로 '반환하지 않음'을 표현합니다.
- 단위 타입(Rust와 Haskell 모두
())을 반환하는 함수는 반환할 수는 있지만 반환값이 없다고 볼 수 있습니다(가능한 값이 하나뿐이기 때문에 무슨 값인지 확인하는 의미가 없으므로). C에서void를 반환하는 함수와 같은 역할을 합니다. - 바닥 타입(Rust에서는 실험 기능인
!, Haskell에서는Void)을 반환하는 함수는 반환 자체를 할 수 없습니다(타입이 맞는 반환할 값을 만들 수 없으므로). C에서_Noreturn이 있는 함수와 같은 역할을 합니다.
이런 체계에서는 바닥 타입 역시 일종의 '일급 타입'이므로 다른 타입과 조합해 더욱 풍부한 의미를 담을 수 있다는 장점이 있습니다. 예를 들어 Rust에서 Result<T, !>는 실패할 수 없는 결과를, Haskell에서 Void -> a는 호출할 수 없는 함수를 나타냅니다.
<declarator> 자세히 살펴보기
<declarator>는 기본적으로 선언하는 것의 이름인 식별자identifier가 중심이 되고, 추가로 다음과 같은 것들로 꾸밀 수 있습니다.
<declarator>가 그렇게 구현된 이유
참고
여기서 1번 떡밥을 마저 회수합니다.
왜
int* x;가 틀리고int *x;가 맞는지 설명할 수 있다.
<declarator>는 <specifiers> 타입을 얻기 위해 거치는 연산을 나타냅니다.
아무 IDE(정 어렵다면 Ideone이나 Compiler Explorer)를 붙잡고 아래 코드를 입력해 보세요.
// 공통 준비 코드
// 타입 확인을 위한 구조체
typedef struct {
int x;
} Foo;
// 값을 이 함수에 넣어서 경고 없이 컴파일이 된다면 타입이 일치하는 것입니다.
void typecheck(Foo x) {}-
Foo x;에서x는Foo입니다.// 이곳에 올바른 타입의 변수를 선언하는 예제 코드가 들어갑니다. Foo x = { 1 }; typecheck(x); -
Foo *x;에서*x는Foo입니다.Foo t = { 2 }, *x = &t; -
Foo x[64];에서x[0]은Foo입니다.Foo x[64] = { { 3 } }; -
Foo *x[4];에서*x[0]은Foo입니다.Foo t = { 4 }, *x[4] = { &t }; -
Foo (*x)[8];에서(*x)[0]은Foo입니다.Foo t[8] = { { 5 } }, (*x)[8] = &t; -
Foo (*(*x[3])[4])[5];에서(*(*x[0])[0])[0]은Foo입니다.Foo t[5] = { { 6 } }, (*u[4])[5] = { &t }, (*(*x[3])[4])[5] = { &u };
<declarator>의 모양과 거치는 식의 모양이 완전히 일치합니다. 여기서는 포인터와 배열 타입만 살펴봤지만, 함수 타입도 이 법칙을 만족합니다. 이것 때문에 사전 지식 없이 처음 C를 접하면 타입 시스템이 헷갈리게 느껴질 수 있는데, 일관적인 시스템이라는 것은 인정하지만 굳이 이렇게 비직관적인 방법을 택해야 했는지는 잘 모르겠습니다.
포인터
T *x;포인터는 개체나 함수의 메모리상의 주소를 값으로 가지는 타입입니다. 단항 역참조 연산 *x를 거치면 타입 T의 값을 얻을 수 있습니다.
배열
T x[n];배열은 같은 타입의 값 여러 개를 메모리상의 인접한 곳에 저장하는 타입입니다. n은 양수여야 하며, 0 이상 n 미만의 i에 대해 배열 원소 접근 연산 x[i]를 거치면 타입 T의 값을 얻을 수 있습니다.
n을 생략할 수 있으며(이 글에서는 '미지의 길이*unknown size'라고 하겠습니다), 이때는 불완전 타입이 됩니다.
다차원 배열
배열의 배열이나 배열의 배열의 배열 따위를 따로 다차원 배열이라고도 하는데, 언어상에서 특별히 다르게 동작하는 것은 아닙니다.
가변 길이 배열variable-length arrays
주의
가변 길이 배열은 구현체에서 선택적으로 지원할 수 있으며, C11 매크로 상수 __STDC_NO_VLA__가 1로 정의되었을 경우 구현체가 가변 길이 배열이나 가변 수식 타입을 지원하지 않습니다.
C23부터는 가변 길이 배열과 가변 수식 타입의 지원이 필수가 되었습니다. 단, 매크로 상수 __STDC_NO_VLA__가 1로 정의되었을 경우 구현체가 자동 기억 기간을 가지는 가변 길이 배열을 지원하지 않습니다.
n에 컴파일 타임 상수가 아닌 식을 넣을 수 있으며, 이를 가변 길이 배열이라고 합니다. 컴파일 시에 길이가 완전히 결정되는 일반 배열과 달리 실제로 선언이 완료된 뒤에야 길이 식을 평가한 값으로 길이가 결정됩니다.
가변 길이 배열이 선언될 때 n이 0 이하의 값으로 평가될 경우에는 비정의 동작이 됩니다.
가변 길이 배열은 선언과 동시에 초기화할 수 없습니다. 단, C23에 추가된 공백 초기화*empty-initialization(정수는 0으로, 실수는 +0으로, 포인터는 널로, 배열/구조체는 모든 멤버를 재귀적으로, 공용체는 첫 멤버를 재귀적으로 공백 초기화)는 가변 길이 배열에도 사용 가능합니다.
int x;
// ❌ 가변 길이 배열을 선언과 동시에 초기화할 수 없습니다.
int foo[x] = { 1 };
// ✅ 가변 길이 배열을 공백 초기화할 수 있습니다 (C23).
int bar[x] = {};가변 길이 배열은 자동이나 할당 기억 기간만을 가질 수 있으며, 연결성은 가질 수 없습니다.
int x, y;
// ✅ 자동 기억 기간을 가지는 가변 길이 배열이 선언되었습니다.
int vla_auto[x];
// ✅ 할당 기억 기간을 가지는 가변 길이 배열이 할당되었습니다.
int (*vla_alloc)[x] = malloc(sizeof(int [x]));
// ✅ 가변 길이 배열의 배열이 할당되었습니다.
int (*vla_multi)[x] = malloc(y * sizeof(int [x]));가변 길이 배열이 포함된 타입을 가변 수식 타입*variably-modified types이라고도 합니다. 가변 수식 타입은 블록 범위나 함수 원형에서만 선언할 수 있으며, 구조체나 공용체는 가변 수식 타입의 멤버를 가질 수 없습니다.
int x;
// ❌ 파일 범위에서 가변 길이 배열을 선언할 수 없습니다.
int foo[x];
// ❌ 파일 범위에서 가변 수식 타입의 변수를 선언할 수 없습니다.
int (*bar)[x];
// ✅ 함수 원형에서 가변 길이 배열이 함수의 인자로 선언되었습니다.
int baz(int y, int [y]);
void fn(void) {
// ❌ 구조체가 가변 길이 배열을 멤버로 가질 수 없습니다.
struct Foo {
int foo[x];
};
}함수
T x(...);함수는 0개 이상의 인자를 받아 값을 반환하는 연산을 나타내는 타입입니다. 함수 호출 연산 x(...)를 거치면 타입 T의 값을 얻을 수 있습니다.
함수는 우측값을 반환하므로 함수의 반환 타입에 한정자를 붙이는 것은 의미가 없으며, 한정자를 붙이지 않은 것처럼 동작합니다.
함수 포인터
함수 타입을 가리키는 포인터를 따로 함수 포인터라고도 하는데, 선언할 때의 문법으로 인해 자칫 함수 포인터를 특별하게 취급하는 것으로 오해할 수 있지만 언어상에서 특별히 다르게 동작하는 것은 아닙니다. 개체가 아닌 함수의 특성상 표준에서는 개체의 포인터와 함수 포인터를 어느 정도 구분하긴 합니다.
가변 인자 함수variadic functions
함수에 매개변수가 하나 이상 있을 경우, 매개변수 목록의 끝에 ...를 추가해 printf처럼 가변 개수의 인자를 받을 수 있습니다. C23부터는 일반 매개변수 없이 가변 인자만 받는 함수도 만들 수 있습니다.
가변 인자 함수에는 호출할 때마다 다른 개수와 타입의 인자를 전달할 수 있습니다. ... 부분으로 전달된 가변 인자에는 <stdarg.h>에서 제공하는 va_start, va_arg, va_end로 접근할 수 있습니다.
#include <stdarg.h>
// ✅ 고정 매개변수 1개를 포함한 가변 인자 함수가 정의되었습니다.
int sum(int count, ...) {
int result = 0;
va_list args;
va_start(args, count);
for(int i = 0; i < count; i++)
result += va_arg(args, int);
va_end(args);
return result;
}K&R 스타일 함수 선언
현재의 C 표준이 있기 전에는 함수를 선언하는 방법이 지금과 많이 달랐습니다. 대표적으로는 함수 원형의 개념이 없었기 때문에 함수를 호출할 떄 타입 검사나 인자의 개수 확인이 이루어지지 않았으며, 함수를 잘못 호출하면 컴파일 오류가 발생하는 대신 비정의 동작이 됩니다. 심지어 C17까지도 매개변수 목록을 생략한 함수 선언 T fn(); 역시 함수 원형이 없는 K&R 스타일 함수 선언입니다.
// ✅👎 K&R 스타일 함수가 정의되었습니다.
// 매개변수 목록에 타입이 작성되어 있지 않습니다.
int old_style_fn(x)
// 매개변수의 타입 정보가 매개변수 목록 바깥에 있습니다.
int x;
{
return x;
}
// ✅👎 매개변수 목록이 생략된 K&R 스타일 함수가 정의되었습니다.
// 이 함수에는 이론상 몇 개의 인자를 넘겨주어도 되지만,
// 같은 프로그램 내에서 `fn`을 다른 개수의 인자로 호출할 경우 비정의 동작이 됩니다.
void fn() {
int x = 1;
double y = 1.2;
// ✅ `old_style_fn`에 `int`를 전달했습니다.
old_style_fn(x);
// 🔥 UB: `old_style_fn`에 `double`을 전달할 수 없습니다.
old_style_fn(y);
// 🔥 UB: `old_style_fn`에 잘못된 개수의 인자를 전달할 수 없습니다.
old_style_fn();
}현재 우리가 알고 있는 함수 원형의 개념은 최초의 표준인 C89에 와서야 정립되었습니다. 매개변수가 없는 함수 원형을 선언하려면 T fn(void);와 같이 매개변수 목록 자리에 void를 넣어야 합니다.
C23부터는 K&R 스타일 함수 선언이 완전히 폐지되며, 매개변수 목록이 생략된 T fn(); 역시 T fn(void);와 같은 의미를 가집니다.
매개변수 타입의 변환
함수는 배열이나 함수를 인자로 받을 수 없습니다. 함수의 매개변수 목록에 배열이나 함수 타입을 작성할 수 있지만, 각각 포인터와 함수 포인터로 일괄 변환됩니다.
// ✅ `int (int *, int [], int (int), int [][4])` (aka `int (int *, int *, int (*)(int), int (*)[4])`) 타입의 함수가 선언되었습니다.
int foo (int *a, int b[], int c (int), int d [4][4]);
// 위 함수의 매개변수 목록은 아래처럼 변환됩니다.
int foo_decayed(int *a, int *b , int (*c)(int), int (*d) [4]);이 동작은 아래에서 설명할 값 변형과 직접적으로 관련되어 있습니다.
가변 길이 배열을 인자로 전달할 수 있습니다. 단, 함수 원형에서는 모든 가변 수식 타입이 [*]으로 변환됩니다.
// ✅ `int (int n, int [n][n])` (aka `int (int, int (*)[*])`) 타입의 함수가 선언되었습니다.
int foo (int n, int arr [n][n]);
// 위 함수의 매개변수 목록은 아래처럼 변환됩니다.
int foo_decayed(int n, int (*arr) [*]);배열 매개변수의 static
매개변수로 (포인터로 변환되는) 배열을 전달할 때 한정자 이외에도 static 키워드를 추가할 수 있습니다. 이 경우에는 널이 아니며 최소한 병기된 길이 이상의 배열을 가리키는 포인터만 인자로 전달해야 합니다.
static int arr4[4], arr8[8];
// ✅ `static`이 병기된 배열 매개변수를 가지는 함수 `foo`가 선언되었습니다.
// 매개변수 `x`에는 길이가 8 이상인 배열만 전달해야 합니다.
void foo(int x[static 8]) {}
void bar() {
// ✅ `foo`에 길이가 8인 배열의 포인터를 인자로 전달했습니다.
foo(arr8);
// 🔥 UB: `foo`에 길이가 8 미만인 배열의 포인터를 전달할 수 없습니다.
foo(arr4);
// 🔥 UB: `foo`에 널 포인터를 전달할 수 없습니다.
foo(NULL);
}파생 타입 조합하기
파생 타입을 여러 가지 순서로 조합해 포인터를 반환하는 함수, 배열을 가리키는 포인터, 다중 포인터 등 여러 가지 타입을 만들 수 있습니다. 단, 모든 경우의 수가 허용되지는 않으며 다음과 같은 조합은 금지됩니다.
- 함수의 배열
- 대신 함수 포인터의 배열을 만들 수 있습니다.
- 배열을 반환하는 함수
- 대신 배열의 첫 원소에 해당하는 포인터를 반환할 수 있습니다.
- 함수를 반환하는 함수
- 대신 함수 포인터를 반환할 수 있습니다.
파생 선언자는 의도적으로 식의 모양과 일치하도록 정해졌기 때문에 파생 타입을 올바르게 조합하려면 단항 연산자의 우선순위를 익혀야 합니다. C의 연산자 우선순위 중 역참조, 배열, 함수 연산자만 살펴보면 다음과 같습니다.
- 후위 연산자
- 함수 호출
() - 배열 원소 접근
[]
- 함수 호출
- 전위 연산자
- 역참조
*
- 역참조
순위가 같은 연산자끼리는 안쪽에서 바깥쪽으로 실행됩니다.
참고
위에 제시된 연산자뿐만 아니라 C의 다른 단항 연산자, 그리고 다른 언어의 단항 연산자도 후위 연산자의 우선순위가 전위 연산자보다 높은 경향을 띠는데, 왜 이런 현상이 일어나는지는 처음 글을 쓴 지 거의 4년 반이 지난 지금도 알지 못하고 있습니다. 일단 저는 -f()가 -(f())가 아니라 (-f)()로 파싱되면 곤란하다는 논리로 받아들이고 있습니다.
위의 연산자 우선순위에 따라 함수 호출과 배열 원소 접근이 역참조보다 우선순위가 높기 때문에 역참조 직후에 함수 호출이나 배열 원소 접근이 필요하다면 괄호를 씌워야 합니다. 역시 같은 논리로 함수의 포인터나 배열의 포인터가 필요하다면 괄호를 씌워야 합니다.
// ✅ `int`를 반환하는 함수 포인터가 선언되었습니다.
// 함수 선언자 `(void)`가 포인터 선언자 `*`보다 우선순위가 높으므로 괄호가 필요합니다.
int (*foo)(void);
// 함수 포인터를 역참조하고 바로 호출할 때 괄호가 필요한 것과 같은 이유입니다.
(*foo)();
// 괄호를 생략하면 포인터를 반환하는 함수가 됩니다.
int *foo2(void);
// ✅ `int`의 배열의 포인터가 선언되었습니다.
// 배열 선언자 `[4]`가 포인터 선언자 `*`보다 우선순위가 높으므로 괄호가 필요합니다.
int (*bar)[4];
// 배열의 포인터를 역참조하고 바로 원소에 접근할 때 괄호가 필요한 것과 같은 이유입니다.
(*bar)[1];
// 괄호를 생략하면 포인터의 배열이 됩니다.
int *bar[4];또한, 식은 안쪽에서 바깥쪽으로 실행되므로 논리적으로 가장 바깥에서 꾸며주는 파생 선언자가 코드상에서는 가장 안쪽으로 들어갑니다.
// ✅ `int`의 배열의 포인터가 선언되었습니다.
// 포인터 선언자 `*`가 안쪽에 있지만 논리적으로는 가장 바깥에 있습니다.
int (*foo)[3];
// ✅ `int`를 반환하는 함수 포인터의 배열이 선언되었습니다.
// 배열 선언자 `[2]`가 함수 선언자 `(int)`보다 안쪽에 있지만 논리적으로는 배열 선언자가 더 바깥에 있습니다.
// 즉, 이 변수는 함수가 아닌 배열입니다.
int (*bar[2])(int);파생 타입 쉽게 읽기
참고
여기서 4번 떡밥을 회수합니다.
int *(*(*x)(char *))[64];와 같은 헷갈리는 선언을 그나마 쉽게 읽을 수 있다.
위에서 언급한 '식expression 논리'역1를 이해했다면 C 타입을 작성하는 것뿐만 아니라 읽는 데도 응용할 수 있습니다. int (*x[8][64])(char *);를 예로 들면, 아래의 단계를 하나씩 밟아나가며 하나의 영어 문장을 완성합니다.
- 식별자를 찾는다. 이 식별자가 파생 타입 읽기의 기준점이 된다.
- "x is a..."
- 우선순위에 따라 파생 선언자를 읽는다.
- 오른쪽으로 훑으면서 파생 타입이 보일 때마다 차례대로 추가한다. 닫는 괄호가 보이거나
<declarator>가 끝나면 멈춘다.- "x is a
[8]of[64]of..."
- "x is a
- 왼쪽으로 훑으면서 파생 타입이 보일 때마다 차례대로 추가한다. 여는 괄호가 보이거나
<declarator>가 끝나면 멈춘다.- "x is a
[8]of[64]of*of..."
- "x is a
<declarator>전체를 읽을 때까지 위의 과정을 반복한다.- "x is a
[8]of[64]of*of(char *)of..."
- "x is a
- 오른쪽으로 훑으면서 파생 타입이 보일 때마다 차례대로 추가한다. 닫는 괄호가 보이거나
- 더 이상 읽을 것이 없으면
<specifiers>로 마무리한다.- "x is a
[8]of[64]of*of(char *)ofint."
- "x is a
- 완성된 문장을 자연어로 바꿀 수 있다.
- "x is an array of size 8×64, of pointers, to functions that accept a pointer to
char, returningint."
- "x is an array of size 8×64, of pointers, to functions that accept a pointer to
- 완성된 자연어 문장을 거꾸로 읽으면 한국어 문장으로도 바꿀 수 있다.
- "x는
int를 반환하는,char의 포인터를 받는 함수의, 포인터의, 길이 8×64의 배열이다."
- "x는
원하는 파생 타입을 코드로 작성하고 싶다면 위 과정을 역순으로 하면 됩니다.
시간이 남는다면 다른 타입에도 연습해보는 게 어떨까요? 아래의 타입을 편한 방식으로 읽어 봅시다.
float **y[4][8];int *(*foo)(int []);char **(*(*z)[123])[456];int *(*(*x)(char *))[64];- 4번 떡밥에서 언급했던 바로 그 타입입니다.
해답
정답 확인하기
float **y[4][8];- y is a
[4]of[8]of*of*offloat. - y is an array of size 4×8, of double pointers, to
floats. - y는
float의, 이중 포인터의, 길이 4×8의 배열이다.
- y is a
int *(*foo)(int []);- foo is a
*of(int [])of*ofint. - foo is a pointer, to a function that accepts an array of
ints, returning a pointer, to anint. - foo는
int의, 포인터를 반환하는,int의 배열을 받는 함수의, 포인터이다.
- foo is a
char **(*(*z)[123])[456];- z is a
*of[123]of*of[456]of*of*ofchar. - z is a pointer, to an array of size 123, of pointers, to arrays of size 456, of double pointers, to
chars. - z는
char의, 이중 포인터의, 길이 456의 배열의, 포인터의, 길이 123의 배열의, 포인터이다. - 맥락상 허용될 경우 '
char의 이중 포인터'를 '문자열의 포인터'로 치환해도 됩니다.
- z is a
int *(*(*x)(char *))[64];- x is a
*of(char *)of*of[64]of*ofint. - x is a pointer, to a function that accepts a pointer to
char, returning a pointer, to an array of size 64, of pointers, toints. - x는
int의, 포인터의, 길이 64의 배열을 반환하는,char의 포인터를 받는 함수의, 포인터이다. - 맥락상 허용될 경우 매개변수로 등장하는 '
char의 포인터'를 '문자열'로 치환해도 됩니다.
- x is a
단독으로 쓰는 타입 이름
타입 변환 연산자나 sizeof 등 선언문 이외에도 타입을 작성하는 곳이 있기 때문에 식별자 없이 타입을 작성해야 하는 경우가 생깁니다. 이 경우에는 (불필요한 괄호가 없다는 가정 하에) 간단히 식별자만 생략해 타입 이름type names으로 만들 수 있습니다.
int v1;
// ✅ `v1`의 타입이 `int`로 작성되었습니다.
sizeof(int);
float v2[5];
// ✅ `v2`의 타입이 `float [5]`로 작성되었습니다.
sizeof(float [5]);
void *v3;
// ✅ `v3`의 타입이 `void *`로 작성되었습니다.
sizeof(void *);
char *v4[64];
// ✅ `v4`의 타입이 `char *[64]`로 작성되었습니다.
sizeof(char *[64]);
char (*v5)[64];
// ✅ `v5`의 타입이 `char (*)[64]`로 작성되었습니다.
sizeof(char (*)[64]);
double (*v6)(double);
// ✅ `v6`의 타입이 `double (*)(double)`로 작성되었습니다.
sizeof(double (*)(double));
int *(*(*x)(char *))[64];
// ✅ `x`의 타입이 `int *(*(*)(char *))[64]`로 작성되었습니다.
sizeof(int *(*(*)(char *))[64]);단, 불필요한 괄호가 있을 경우 식별자를 생략하면 함수 선언자로 인식될 수 있습니다.
// ✅ `int` 타입의 변수 `v7`이 선언되었습니다.
int (v7);
// 🔥 `v7`의 타입이 아닌 `int ()` (`int`의 함수)로 인식됩니다.
sizeof(int ());저는 이런 이유로 타입 이름을 작성할 떄도 int*보다 int *가 더욱 올바르다고 봅니다.
보충: 사실 C++도 대체로 같습니다
C++의 타입 시스템에는 C라는 기반 위에 무언가 여러 가지 복잡한 것들이 추가되었고 의미도 많이 바뀌었지만, 적어도 파생 선언자는 어느 정도 비슷하게 사용할 수 있습니다. C와 비교하자면 다음과 같습니다.
- 기존의 3가지 파생 선언자에 다음 두 파생 선언자가 추가되었습니다. 참조 타입에 대응하는 연산자가 없기 때문에 '식 논리'가 완전히 성립하는 것은 아닙니다.
- 좌측값 참조
T &x; - C++11 우측값 참조
T &&x;(참조의 참조가 아닙니다!)
- 좌측값 참조
- 매개변수 자리의 배열과 함수가 포인터로 일괄 변환됩니다.
- C에서 금지되는 파생 타입 조합은 C++에서도 금지되며, 추가로 다음 조합도 금지됩니다.
- 참조의 포인터
- 참조의 배열
- 참조의 참조
- '식 논리'와 연산자 우선순위에 의해 (배열이나 함수)의 (포인터나 참조)를 만들 때는 괄호가 필요합니다.
T &x();는 참조를 반환하는 함수이고,T (&x)();는 함수의 참조입니다.
- 연산자 우선순위를 따라가면서 읽을 수 있습니다.
- 식별자를 생략해 타입 이름으로 만들 수 있습니다.
C++에서 클래스 T를 사용해 T x();라고 선언했는데 생성자 T::T()가 호출되지 않는 것도 x가 T를 반환하는 함수(aka T ())로 선언되었기 때문입니다.4
위와 같은 이유로 저는 C++에서 참조를 선언할 때도 T& x;보다 T &x;가 더욱 올바르다고 봅니다.
값 카테고리value categories
C의 모든 식에는 타입뿐만 아니라 값 카테고리도 같이 부여되며, 그 식이 메모리상의 위치를 나타내는지 메모리와 무관한 순수 값을 나타내는지를 결정합니다.
C에는 다음과 같은 세 가지 값 카테고리가 있습니다.
참고
'좌측값'과 우측값의 형식적인 이름인 '비좌측값 개체non-lvalue object'이라는 이름은 (주로) 대입 연산자 =의 좌변에 올 수 있거나 없다는 의미에서 붙여진 이름이며, '값'이라고 부르지만 실제로는 식을 분류하는 개념이기 때문에 다소 비직관적으로 느껴질 수도 있습니다.
Rust에서는 '좌측값'과 '우측값' 대신 실제 의미를 반영해 '자리식place expressions'과 '값식value expressions'이라는 표현을 사용하고 있으며, 특히 대입 연산자의 좌변에 오는 식을 '피대입식*assignee expressions'이라고 합니다.
좌측값lvalue
좌측값은 메모리상의 실제 개체를 가리키는 식을 나타내며, 실제 메모리 위치에 수행해야 말이 되는('좌측값 맥락lvalue context') 다음과 같은 연산을 할 수 있습니다.
- 주소 획득 (
&x) - 쓰기 연산
- 단항 증감 연산 (
x++,x--,++x,--x) - 단순/복합 대입 연산자의 좌변 (
x = y)- '좌측값'이라는 용어의 유래가 이것입니다.
- 수정 가능한 좌측값이 아닐 경우는 예외입니다.
- 단항 증감 연산 (
- 멤버 접근 연산자의 좌변 (
x.y)- 우측값도 멤버 접근이 가능하지만, 그 결과가 좌측값이 아닌 우측값이 됩니다.
좌측값에 해당하는 식은 다음과 같습니다.
- 함수 지시자나 열거형 상수를 제외한 모든 식별자
- 문자열 리터럴
- C99 복합 리터럴
- 좌측값 구조체의 멤버 (
x.y) - 구조체 포인터의 멤버 (
p->y) - 개체 포인터의 역참조 (
*p) - 배열의 원소 (
x[]) - 좌측값인 식에 괄호를 씌운 것
- 예외적으로
void타입의 식은 우측값으로 취급됩니다.
참고로 아래의 식은 C++에서는 좌측값이지만 C에서는 좌측값이 아닙니다.
- 기본 단순/복합 대입 연산 (
x = y)- 대입 연산자도 식의 일부로 취급하며, C에서는 대입하고 난 뒤 좌변의 값, C++에서는 대입하고 난 뒤의 좌변 개체로 평가됩니다.
- 기본 전위 증감 연산 (
++x,--x)- 기본 후위 증감 연산(
x++,x--)은 C++에서도 우측값(구체적으로는 순우측값*prvalue)입니다.
- 기본 후위 증감 연산(
- 우변이 좌측값인 기본 콤마 연산 (
y, x) - 참/거짓 변이 모두 좌측값인 조건 연산 (
y ? x1 : x2)
수정 가능한 좌측값modifiable lvalue
대부분의 좌측값에는 쓰기 연산을 할 수 있지만, 예외적으로 아래에 해당하는 좌측값에는 쓰기 연산을 할 수 없습니다.
- 불완전 타입을 가지는 식
- 배열
- 단, 구조체나 공용체로 감싸져 있을 경우에는 구조체/공용체 자체에 쓰기 연산을 함으로써 우회할 수 있습니다.
const한정된 타입을 가지는 식const한정된 멤버가 (재귀적으로) 하나라도 있는 식
우측값rvalue
우측값의 엄밀한 이름은 '비좌측값 개체non-lvalue object'이지만, 우측값이라는 이름도 자주 사용합니다.
우측값은 메모리상에 존재하지 않고 값으로만 존재하는 '추상적인' 개체 타입의 식을 나타냅니다. 메모리상에 없기 떄문에 주소도 획득할 수 없습니다.
좌측값이 아닌 개체 타입의 값은 모두 우측값이며, 좌측값이더라도 메모리 조작이 필요 없을 경우 읽기 연산을 통해 우측값으로 변환됩니다.
함수 지시자*function designator
함수는 개체 타입이 아니므로 좌측값도 우측값도 될 수 없으며, 함수를 가리키는 식은 특별히 함수 지시자라고 합니다.
함수는 함수 지시자 그대로는 쓸모가 없으며, 명시적으로든 암시적으로든 항상 함수 포인터로 변환됩니다.
불완전 타입incomplete types
참고
여기서 5번 떡밥을 회수합니다.
왜 다차원 배열의 맨 처음 길이만 생략할 수 있는지 이해할 수 있다.
타입이 선언은 되었는데 아직 완전히 정의되지 않아서 실제로 사용할 수 없는 경우가 있고, 특히 타입의 크기를 알 수 없는 경우가 있으며, 이를 불완전 타입이라고 합니다.
불완전 타입에는 다음과 같은 것들이 있습니다. 이 글에서는 불완전 타입을 완전 타입으로 만드는 것을 '완성한다*complete'고 하겠습니다.
void- 완성할 수 없습니다.
- 미지의 길이를 가지는 배열 타입 (
T [])- 함수의 매개변수로 등장해 포인터로 변환되는 경우와 C99
T [*]는 여기에 해당하지 않습니다. - 최초 선언과 동시에 초기화하는 경우, 또는 나중에라도 같은 배열을 재선언과 동시에 초기화할 경우 우변의 중괄호가 닫히는 순간 완성되며, 길이는 우변으로부터 추론됩니다.
- 함수의 매개변수로 등장해 포인터로 변환되는 경우와 C99
- 구조체나 공용체 타입
- 최초 선언과 동시에 정의하는 경우, 또는 나중에라도 같은 구조체나 공용체를 정의할 경우 정의부의 중괄호가 닫히는 순간 완성됩니다.
(소스 코드상에서의 위치 기준으로) 아직 완성되지 않은 불완전 타입은 소스 코드에서 나중에 완성되더라도 대부분의 상황에서 타입으로 사용할 수 없습니다. 이는 구조체나 공용체가 자기 자신을 멤버로 가질 수 없게 하는, 즉 재귀적 타입을 차단하는 효과를 가집니다.
// ✅ 불완전 `int []` 타입을 가지는 변수 `arr`가 선언되었습니다.
int arr[];
int foo(void) {
// ❌ 불완전 타입의 크기를 구할 수 없습니다.
// `arr`의 타입이 아래에서 완성되지만 이 시점에는 아직 불완전 타입입니다.
return sizeof(arr);
}
// ✅ `arr`의 정의와 동시에 타입이 `int [1]`로 완성되었습니다.
int arr[1] = { 1 };
struct Foo {
// ❌ 불완전 타입을 멤버로 가질 수 없습니다.
// `struct Foo` 타입이 아래에서 완성되지만 이 시점에는 아직 불완전 타입입니다.
struct Foo child;
// ✅ 불완전 타입의 포인터 타입의 멤버가 선언되었습니다.
struct Foo *child_ptr;
};불완전 타입과 파생 선언자 타입은 다음과 같이 상호작용합니다.
-
불완전 타입의 포인터를 만들 수 있습니다.
- 특히
void *타입이 여기에 해당합니다. - 나중에 완성되는 타입은 안전하게 역참조도 가능합니다. 구조체나 공용체가 자기 자신을 포인터로 참조할 수 있는 이유도 이것입니다.
- 포인터 산술이 필요한 연산(
++p,p + 4,p[2]등)은 가리켜지는 타입의 크기가 필요하므로 불가능합니다.
- 특히
-
불완전 타입의 배열을 만들 수 없습니다.
-
다차원 배열을 선언할 때 맨 처음(즉, 논리적으로 가장 바깥) 길이만 생략할 수 있는 이유도 이것입니다. 선언과 동시에 초기화를 하는 경우에도 가장 바깥을 제외한 안쪽 배열의 길이는 추론되지 않습니다.
// ✅ `int`의 완전 배열(`[2]`)의 완전 배열(`[2]`)의 불완전 배열(`[]`)이 선언되었습니다. int x[][2][2]; // ❌ 불완전 배열(`int [][2]`)의 배열을 선언할 수 없습니다. int y[2][][2];
-
-
불완전 타입을 반환하는 함수를 만들 수 없습니다.
- 단,
void를 '반환하는' 함수는 예외이며, 반환문을 아예 사용하지 않거나 반환값을 생략한return;꼴의 반환문만 사용할 수 있습니다.
- 단,
타입 변환
타입 변환은 원래 값의 정보를 최대한 보존하면서 다른 타입의 값으로 변환하는 과정입니다.
C에서는 여러 가지 상황에 여러 가지 타입 변환이 일어나는데, 어떤 상황에 어떻게 변환되는지 정리해 보겠습니다.
호환성
서로 다른 번역 단위에서 같은 개체에 다른 타입을 매기려면 그 의미와 표현이 충분히 비슷해서 같은 타입으로 볼 수 있어야 하는데, 이 경우 두 타입이 '호환된다compatible'고 합니다. 호환되는 타입끼리는 별도의 연산 없이 그대로 변환이 가능합니다.
두 타입이 호환될 조건은 다음과 같습니다. 아래의 조건은 위에서 언급했던 '별도의 연산 없이 그대로 대입해도 문제가 없는 경우'로 요약할 수 있습니다.
목록 펼치기
- 타입 시스템상에서 완전히 같은 타입일 경우
typedef타입 동의어도 같은 타입으로 취급합니다.
- 호환되는 타입의 똑같이 한정된 타입일 경우
- 호환되는 타입을 가리키는 포인터 타입일 경우
- 둘 모두가 배열이며, 다음을 모두 만족할 경우
- 두 타입의 원소 타입이 호환된다.
- 두 배열의 길이가 컴파일 타임 상수인 경우에 한해, 완전히 같은 길이를 가진다.
- 둘 모두가 구조체/공용체/열거형 중 같은 종류이며, 다음을 모두 만족할 경우
- 한쪽이 열거형이고, 다른 한쪽이 그 열거형의 기반 타입일 경우
- 둘 모두가 함수이고, 다음을 모두 만족할 경우
- 두 함수의 반환 타입이 호환된다.
- 두 함수 모두 매개변수 목록이 있는 경우에 한해, 매개변수의 개수와 가변 인자 여부가 같으며, 매개변수 타입 변환과 최상위 한정자 제거를 거친 뒤 대응하는 매개변수 타입이 호환된다.
- 한쪽이 매개변수 목록이 있고 다른 한쪽이 K&R 스타일 선언일 경우에 한해, 전자가 가변 인자 함수가 아니고 전자의 매개변수가 디폴트 인자 승격의 영향을 받지 않는다.
- 한쪽이 매개변수 목록이 있고 다른 한쪽이 K&R 스타일 정의일 경우에 한해, 두 함수의 매개변수의 개수가 같고 전자의 각 매개변수가 디폴트 인자 승격을 거치고 나서 후자의 대응하는 매개변수와 호환된다.
합성 타입*composite types
같은 개체에 호환되지만 서로 다른 타입을 매길 경우 두 타입의 '교집합'을 찾는데, 이를 합성 타입이라고 합니다. 합성 타입을 구하는 규칙은 다음과 같습니다.
목록 펼치기
- 배열의 합성 타입
- 한쪽의 길이가 컴파일 타임 상수일 경우, 그 길이를 가지는 배열이 합성 타입이 된다.
- C99 한쪽이 길이가 지정된 가변 길이 배열이지만 그 길이가 평가되지 않은 경우, 합성 타입을 구하려고 하면 비정의 동작이 된다.
- C99 한쪽이 길이가 지정된 가변 길이 배열이고 그 길이가 평가된 경우, 그 길이를 가지는 배열이 합성 타입이 된다.
- C99 한쪽이 길이가 지정되지 않은 가변 길이 배열일 경우, 길이가 지정되지 않은 가변 길이 배열이 합성 타입이 된다.
- 둘 모두 미지의 길이를 가질 경우, 미지의 길이를 가지는 배열이 합성 타입이 된다.
- 합성된 배열의 원소는 두 배열의 원소의 합성 타입을 가진다.
- 함수의 합성 타입
- 둘 중 하나가 K&R 스타일 함수이고 다른 하나는 매개변수 목록이 있을 경우, 후자의 매개변수 목록을 가지는 함수 원형이 합성 타입이 된다.
- 둘 모두 매개변수 목록이 있을 경우, 대응하는 매개변수끼리의 합성 타입을 구한다.
암시적 변환
암시적 변환은 프로그래머가 의도적으로 타입 변환 연산자를 사용하지 않아도 자동으로 타입 변환이 일어나는 경우를 일컫습니다.
보통 산술 변환에서 부호 없는 타입을 '선호하는' 현상을 제외하면 대부분 상식 선에서 변환이 일어나고, 핵심을 요약하자면 다음과 같습니다.
- 호환되는 타입끼리 암시적 변환이 된다.
- 산술 타입끼리 암시적 변환이 된다.
- 비
void와void포인터 사이에 암시적 변환이 된다. 0은 아무 널 포인터로 암시적 변환이 된다.- C99
_Bool로 변환할 때는 0과 일치하지 않으면 무조건true가 된다.
적용되는 상황과 목표 타입
대입할 때처럼 변환conversion as if by assignment
다음과 같은 대입에 준하는 상황에 대입되는 변수의 타입으로 변환됩니다.
- 단순/복합 대입 연산 (
y = x) - 선언과 동시에 초기화 (
T y = x;,T y = { x };) - 함수 호출 시 인자 전달 (
f(x)) - 함수에서 반환 (
return x;)
디폴트 인자 승격*default argument promotions
인자를 전달할 때 다음과 같이 함수 원형을 참고할 수 없는 상황에 정수 타입은 승격되고, 실수인 float은 double로 변환됩니다. (허수와 복소수는 변환되지 않습니다.)
- K&R 스타일 함수의 모든 인자
- 가변 인자 함수의 가변 인자
보통 산술 변환*usual arithmetic conversions
다음과 같은 산술 연산자를 사용할 때 모든 피연산자가 정수 승격과 함께 아래에서 설명할 공통 실수 타입*common real type에 대응하는 실수/순허수/복소수 타입으로 변환됩니다. 이때 양쪽 모두가 실수이면 실수, 순허수이면 순허수, 이외의 경우에는 복소수 타입이 됩니다.
- 이항 산술 연산자
+,-,*,/,% - 관계 연산자
==,!=,<,<=,>,>= - 이항 비트 연산자
&,|,^ - 조건 연산자
?..:의 참/거짓 변
공통 실수 타입을 구하는 규칙은 다음과 같습니다.
목록 펼치기
- C23 피연산자 중 하나라도 십진 부동소숫점 타입일 경우, 다른 피연산자가 이진 부동소숫점이어서는 안 된다.
- 양쪽 피연산자의 타입을 아래의 '크기 순서'대로 비교해서 가장 큰 것이 공통 실수 타입이 된다. 해당하는 타입이 없으면 다음으로 넘어간다.
_Decimal128_Decimal64_Decimal32long doubledoublefloat
- 이 시점에서는 양쪽 피연산자가 모두 정수 타입으로, 정수 승격을 수행한다.
- 양쪽 타입이 같으면 그 타입이 공통 실수 타입이 된다.
- 양쪽 타입의 부호 유무가 같으면 둘 중 정수 변환 등급이 높은 타입이 공통 실수 타입이 된다.
- 부호 없는 타입의 등급이 다른 타입 이상일 경우 그 타입이 공통 실수 타입이 된다.
- 부호 있는 타입이 부호 없는 타입의 값을 모두 표현할 수 있을 경우 그 타입이 공통 실수 타입이 된다.
- 부호 없는 타입에 부호를 추가한 타입이 공통 실수 타입이 된다.
정수 승격*integer promotions
정수 승격은 int/unsigned int 미만의 '정수 변환 등급'을 가지는 정수 타입과 기반 타입이 _Bool, int, signed int, unsigned int인 비트필드가 int나 unsigned int로 변환되는 것을 일컫습니다. 기존 타입이나 비트필드의 모든 값을 int로 나타낼 수 있으면 int, 그렇지 않으면 unsigned int가 선택됩니다. 단, C23 비트 정수는 정수 승격을 거치지 않으며, 비트 정수에 기반하는 비트필드는 기반하는 타입으로 변환됩니다.
정수 승격은 대표적으로 디폴트 인자 승격과 보통 산술 변환에서 나타나지만, 다음 연산자에서도 보통 산술 변환 없이 정수 승격이 발생합니다.
- 단항 산술 연산자
+,- - 단항 비트 연산자
~ - 비트 시프트 연산자
<<,>>의 양변에 독립적으로
정수 변환 등급*integer conversion rank
정수 변환 등급은 다음과 같은 규칙으로 결정되는 추이적 관계입니다. 이렇게 정의된 등급 관계는 보통 산술 변환과 정수 승격에서 '더 큰 타입'을 찾는 데 사용합니다.
목록 펼치기
- 부호 있는 정수 타입끼리는 모두 등급이 다르며, 크기가 큰 타입이 등급이 높다.
signed char<short<int<long<long long
- 부호 없는 정수 타입의 등급은 대응하는 부호 있는 타입과 같다.
- C99 확장 정수 타입과 C23 비트 정수의 등급은 같은 크기를 가지는 표준 정수 타입의 등급보다 낮다.
char,signed char,unsigned char의 등급은 모두 같다._Bool(C23bool)의 등급은 다른 어떤 표준 정수 타입보다도 낮다.- 열거형의 등급은 그 기반 타입과 같다.
- C23 부호 있는 비트 정수의 등급은 그 미만의 크기를 가지는 어떤 표준 정수 타입이나 비트 정수보다도 높다.
- 확장 정수 타입끼리, 혹은 C23 비트 정수와 확장 정수 타입 사이의 등급 관계는 구현체 정의 동작에 해당한다.
암시적 변환의 의미
암시적 변환은 다음과 같은 두 단계를 거칩니다.
값 변형*value transformations
우측값으로써 사용되는 좌측값이나 함수 지시자는 그 자체로는 직접 사용할 수 없으며, 다음과 같은 변환을 거칩니다.
좌측값 변환lvalue conversion
좌측값 중 배열이 아니고, 좌측값 맥락이나 sizeof 연산자의 인자로 쓰이지 않는 것은 암시적으로 우측값으로 변환됩니다. 이 연산은 메모리상의 위치에서 실제 값을 획득하는 연산, 즉 읽기 연산에 해당하는 변환입니다.
한정자와 원자성은 (좌측값) 개체의 의미를 바꾸는 언어 기능이므로 좌측값 변환을 거치는 타입은 한정자와 원자성을 잃습니다. 아래에서 살펴볼 명시적 변환의 결과도 우측값이므로 한정된 타입으로 명시적 변환을 해도 의미가 없고, 주소 획득과 역참조를 거쳐야 합니다.
int x = 0;
// ❌ 우측값에 대입할 수 없습니다.
(const int)x = 1;
// ❌ 좌측값이므로 `const`가 효력을 가지며, 대입할 수 없습니다.
*(const int *)&x = 1;
// 🔥 우측값을 `volatile` 한정할 수 없으므로 읽기 연산이 보장되지 않습니다.
(void)(volatile int)x;
// ✅ `x`에 대한 읽기 연산이 수행되었습니다.
(void)*(volatile int *)&x;좌측값 변환을 거치는 값이 불완전 타입을 가지거나, 자동 기억 기간을 가지고 주소가 획득된 적도(scanf 등의 함수에 포인터를 전달해 초기화하는 경우가 있으므로) 초기화나 대입된 적도 없을 경우에는 비정의 동작이 됩니다.
배열에서 포인터로 변환array to pointer conversion
참고
여기서 6번 떡밥을 회수합니다.
배열과 포인터가 정확히 어떻게 다른지 이해할 수 있다.
좌측값 중 배열이고, 좌측값 맥락이나 sizeof/C23 typeof/typeof_unqual 연산자의 인자로도, char * 타입의 초기화에도 쓰이지 않는 것은 좌측값 변환 대신 배열에서 포인터로 변환을 거치며, 암시적으로 그 배열의 첫 번째 원소를 가리키는 우측값 포인터로 변환됩니다.
C에서 배열에서 포인터로 변환이 암시적으로 이루어지기 때문에 배열과 포인터가 비슷하다는 인상을 주는데, 이 둘은 전혀 다른 동작을 하는 서로 다른 타입입니다. 대표적으로 다음과 같은 차이를 보입니다.
-
포인터는 수정할 수 있지만, 배열은 수정할 수 없습니다.
- 대입 연산자 좌변의 배열이 우측값으로 바뀌기 때문입니다.
int a[1] = { 1 }, b[1] = { 2 }, *c = a, *d = b; // ❌ `a`는 배열 타입이었지만 우측값으로 변환되었으므로 대입할 수 없습니다. a = b; // ❌ 우측값에 증감 연산을 할 수 없습니다. a++; // ✅ 포인터 타입을 가지는 `c`에 새로운 값이 대입되었습니다. c = d; // ✅ 포인터에 증감 연산이 수행되었습니다. c++; -
배열과 포인터의
sizeof가 다릅니다. -
포인터에는 배열 원소 접근(
x[i])이 가능하지만, 배열에는 불가능합니다.-
이게 무슨 뚱딴지같은 소리냐고 할 수 있지만, 배열에 배열 원소 접근을 할 수 있는 것처럼 보이는 것은 배열이 이미 포인터로 바뀌었기 때문입니다.
6.5.3.2 배열 원소 접근
제한
- 두 식 중 하나의 타입은 "완전한 개체 타입의 포인터", 다른 하나의 타입은 정수 타입을 가져야 하며, 그 결과는 "타입" 타입을 가진다.
-
추가로 배열 원소 접근 연산
x[i]자체가*(x + i)의 문법적 설탕으로 정의되어 있습니다."foo"[1]과1["foo"]가 같은 동작을 하는 것도 같은 원리입니다.
대괄호
[]로 둘러싸인 식이 따라붙는 후위식은 배열 개체의 원소를 첨자로 지시한 것이다. 배열 원소 접근 연산자[]는E1[E2]가(*((E1)+(E2)))과 동일하도록 정의된다. 이항+연산자에 적용되는 변환 규칙에 의해, E1이 배열 개체 (즉, 배열 개체의 첫 원소를 가리키는 포인터)이고, E2가 정수일 경우,E1[E2]는 (0부터 세어서) E1의 E2번째 원소를 가리킨다.
-
-
배열의 포인터와 포인터의 포인터끼리 서로 대입하려고 하면 잘못된 동작을 합니다.
int (*pa)[1] = 0, **pb = 0; // 제가 아는 한 아래의 두 문장 모두 UB의 가능성이 있습니다. // 🔥 포인터의 포인터를 호환되지 않는 타입인 배열의 포인터에 대입할 수 없습니다. pa = pb; // 🔥 배열의 포인터를 호환되지 않는 타입인 포인터의 포인터에 대입할 수 없습니다. pb = pa;
register 개체의 주소를 획득할 수 없다는 규칙에 의해, 변환을 거치는 배열이 register일 경우에는 비정의 동작이 됩니다.
함수에서 포인터로 변환function to pointer conversion
함수 지시자이고, 주소 획득(&)이나 sizeof/C23 typeof/typeof_unqual 연산자의 인자로 쓰이지 않는 것은 함수에서 포인터로 변환을 거치며, 암시적으로 그 함수 지시자가 가리키는 함수의 우측값 포인터로 변환됩니다.
위에서 다룬 배열과 포인터의 비슷한 듯 다른 관계가 함수와 함수 포인터에도 비슷하게 적용됩니다.
-
함수 포인터는 수정할 수 있지만, 함수 자체는 수정할 수 없습니다.
- 대입 연산자 좌변의 함수 지시자가 우측값으로 바뀌기 때문입니다.
int f(int), g(int), (*a)(int) = f, (*b)(int) = g; // ❌ `f`는 함수 타입이었지만 우측값으로 변환되었으므로 대입할 수 없습니다. f = g; // ✅ (함수의) 포인터 타입을 가지는 `a`에 새로운 값이 대입되었습니다. a = b; -
함수 포인터와 달리 함수 자체의
sizeof를 구하려고 하면 비정의 동작이 됩니다. -
함수 포인터에는 함수 호출(
f())이 가능하지만, 함수 자체에는 불가능합니다.- 이게 무슨 뚱딴지같은 소리냐고 할 수 있지만, 함수에 함수 호출을 할 수 있는 것처럼 보이는 것은 함수가 이미 함수 포인터로 바뀌었기 때문입니다.
6.5.3.3 함수 호출
제한
- 호출되는 함수를 가리키는 식90)은
void를 반환하거나 배열 타입이 아닌 완전한 개체 타입을 반환하는 함수의 포인터를 타입으로 가져야 한다.
90) 이는 함수 지시자인 식별자가 변환된 결과인 경우가 대다수이다.
추가로 함수에서 포인터로 변환에 의해 다음과 같은 재미있는 동작이 성립합니다.
-
함수 포인터를 초기화하거나 대입할 때
&를 써도, 쓰지 않아도 됩니다.- 함수 지시자를 그대로 사용할 경우 함수 포인터로 변환됩니다.
- 함수 지시자의 주소를 획득할 경우 주소 획득 예외에 의해 함수에서 포인터로 변환이 이루어지지 않는데, 바로 이어지는 주소 획득이 함수에서 포인터로 변환과 같은 동작을 합니다.
void foo(void) {} void bar(void) { void (*f)(void); // ✅ `foo`가 암시적 변환을 통해 포인터로 변환되었습니다. f = foo; // ✅ `foo`가 주소 획득을 통해 포인터로 변환되었습니다. f = &foo; } -
함수 포인터를 무한정 역참조할 수 있습니다.
- 함수 포인터를 역참조해도 도로 함수 포인터로 변환되기 때문입니다.
void foo(void) {} void bar(void) { // ✅ `foo`가 호출되었습니다. (**********************foo)(); }
응용: 다차원 배열 할당
참고
여기서 7번 떡밥을 회수합니다.
단 한 번의
malloc호출로 다차원 배열을 동적 할당받을 수 있다.
사실은 이 글에 '당신은 2차원 배열 동적 할당을 99.9% 잘못 배웠다' 같은 부제목을 넣고 싶었지만 그건 어그로성이 너무 짙어서 하지 않기로 했습니다.
C에서 2차원 (n×m) 배열을 동적 할당할 때는 보통 다음과 같은 방법을 배웁니다.
int **arr_2d = malloc(n * sizeof(int *));
for(int i = 0; i < n; i++)
arr_2d[i] = malloc(m * sizeof(int));참고
C++에서와 달리, C에서는 암시적 변환 규칙으로 인해 malloc 호출을 명시적으로 타입 변환하지 않아도 됩니다.
이렇게 하면 malloc도 free도 n + 1번 해야 되니 꽤나 불편합니다. 게다가 메모리 공간을 여러 번 할당받으므로 배열 공간 전체가 연속이라는 보장이 없습니다.
길이가 서로 다른 (특히 길이가 도중에 바뀔 수도 있는) 배열 n개의 배열(jagged array라고 합니다)이 필요하다면 일반적으로 이 이외에 뾰족한 방법이 없고, 이 방법을 그대로 쓰면 됩니다. 그 대신, 길이가 m으로 고정된 배열 n개의 배열이라면 더 좋은 방법이 있습니다.
위에서 보았듯 배열은 그 자체로는 사용할 수 없기 때문에 함수의 반환값으로 배열을 반환할 수 없고, malloc 역시 같은 이유로 배열이 아닌 포인터를 반환합니다. 즉, 위의 첫 번째 malloc 호출에서 반환하는 논리적인 타입은 코드에 작성된 그대로 int **가 아닌 int *[m]이 됩니다. 어라, 2차원 배열을 쓴다더니 왜 포인터의 배열이 있나요?
다행히 C에는 배열의 배열 타입(int [n][m])이 있고, malloc에서 반환할 수 있도록 배열의 포인터(int (*)[m])로도 변환할 수 있습니다.
int (*arr_2d)[m] = malloc(n * sizeof(int [m]));이렇게 할당된 arr_2d는 int [n][m] 타입으로 선언된 것과 같은 메모리 표현을 가지고, 거의 같은 방법으로 사용할 수 있습니다. 컴파일러가 가변 길이 배열을 지원하지 않을 경우에는 사용성이 다소 떨어지겠지만, 이 경우에도 안쪽 배열의 길이를 컴파일 시에 알 수 있다면(예를 들어 int [n][3]) 문제 없이 사용할 수 있습니다.
이 방법으로 3차원 이상의 고차원 배열도 할당할 수 있으며, 이론상으로는 17114번 '하이퍼 토마토'도 11차원 배열을 할당받아 풀 수 있습니다.
int (*arr_3d)[b][c] = malloc(a*sizeof(int [b][c]));
int (*arr_4d)[b][c][d] = malloc(a*sizeof(int [b][c][d]));
// 차원이 높아질수록 아래와 같이 `sizeof 식` 꼴로 작성하는 것이 편합니다.
int (*arr_3d_alt)[b][c] = malloc(a*sizeof *arr_3d_alt);
int (*arr_4d_alt)[b][c][d] = malloc(a*sizeof *arr_4d_alt);참고로 할당을 해제할 때도 한 번만 해제하면 됩니다.
free(arr_2d);타입 간 변환
목록 펼치기
- 호환되는 타입끼리
- 아무것도 하지 않습니다.
- 정수끼리
- 목표 타입이 기존 값을 나타낼 수 있으면 목표 타입의 대응하는 값으로 변환됩니다.
- 그렇지 않을 경우 목표 타입의 부호 유무에 따라 처리가 다릅니다.
unsigned: 목표 타입의 비트 수에 대해 를 취한 값으로 변환됩니다. signed: 구현체에서 정의하는 방법으로 변환됩니다.
- 실수끼리
- 목표 타입이 기존 값을 정확하게 나타낼 수 있으면 목표 타입의 대응하는 값으로 변환됩니다.
- 목표 타입이 기존 값을 부정확하게 나타낼 수 있으면 가장 가까운 수로 올림하거나 버림합니다. 둘 중 어떤 동작을 하는지는 구현체 정의 동작에 해당합니다.
- 단, 부동소숫점 표준을 만족할 경우 둘 중 더 가까운 수로 근사합니다.
- 목표 타입이 나타낼 수 없는 기존 값을 변환하려고 하면 비정의 동작이 됩니다.
- 단, 부동소숫점 표준을 만족할 경우 부동소숫점 표준을 따릅니다. 정확하지는 않지만 양/음의 무한대로 변환되는 것으로 알고 있습니다.
- 포인터끼리
void *는 아무 개체 타입의 포인터와 변환할 수 있습니다.- 기존 포인터를 변환했다가 돌려놓았을 때 비정의 동작이 일어나지 않는다면 그 포인터 값은 원래와 같습니다.
- 한정되지 않은 타입의 포인터에서 한정된 타입의 포인터로 변환할 수 있습니다. 단, 역방향으로는 변환할 수 없습니다.
- 변환 전후의 포인터 값은 같습니다.
const,volatile,restrict를 독립적으로 판단합니다. 즉,T *에서const T *뿐만 아니라volatile T *에서const volatile T *와 같은 변환도 가능합니다.
- 정수 상수
0이나(void *)0, 매크로식NULL,nullptr는 아무 개체·함수 타입의 널 포인터로 변환할 수 있으며, 널이 아닌 어떤 포인터와도 같지 않음이 보장됩니다. 단, 역방향으로는 변환할 수 없습니다.
- C99 스칼라 타입에서
_Bool로- 기존 값이
0과 같을 경우 (C23 산술 타입은 0, 포인터 타입은 널,nullptr_t는 무조건)false, 그렇지 않을 경우true로 반환됩니다. 이때0.5나 허수 단위I등의 값도0과 같지만 않으면 무조건true가 됩니다.
- 기존 값이
- 정수에서 실수로
- 목표 타입이 기존 값을 정확하게 나타낼 수 있으면 목표 타입의 대응하는 값으로 변환됩니다.
- 목표 타입이 기존 값을 부정확하게 나타낼 수 있으면 가장 가까운 수로 올림하거나 버림합니다. 둘 중 어떤 동작을 하는지는 구현체에서 정의합니다.
- 단, 부동소숫점 표준을 만족할 경우 둘 중 더 가까운 수로 근사합니다.
- 목표 타입이 나타낼 수 없는 기존 값을 변환하려고 하면 비정의 동작이 됩니다.
- 단, 부동소숫점 표준을 만족할 경우 비명시 값으로 변환됩니다.
- 실수에서 정수로 (
_Bool제외)- 기존 값을 0 방향으로 버립니다(즉, 소숫점 아래를 버립니다).
- 목표 타입이 이 값을 나타낼 수 없을 경우 비정의 동작이 됩니다.
- 실수-허수-복소수 간
- 실·허수부를 따로 처리합니다. 아래에서 '실수부'라고 서술한 것은 허수부에 대해서도 동일합니다.
- 실수부가 기존 타입에 있지만 목표 타입에는 없는 경우 실수부를 버립니다.
- 실수부가 기존 타입에는 없지만 목표 타입에 있는 경우 +0으로 변환합니다.
- 실수부가 기존 타입과 목표 타입에 모두 있는 경우 실수끼리 변환 규칙에 준합니다.
- 실·허수부를 따로 처리합니다. 아래에서 '실수부'라고 서술한 것은 허수부에 대해서도 동일합니다.
명시적 변환
명시적 변환은 전위 (T) 연산자를 사용해 프로그래머가 의도적으로 타입을 변환하는 경우를 일컫습니다. 핵심을 요약하자면 다음과 같습니다.
- 암시적 변환이 된다면 명시적 변환도 된다.
(void)로 '변환'도 의외로 가능하다.- 정수 타입과 포인터끼리 변환이 된다.
- 개체 타입의 포인터끼리 변환이 된다.
- 함수 포인터끼리 변환이 된다.
명시적 변환의 의미
대입할 때처럼 암시적 변환이 가능하다면 그 방법을 사용합니다. 그렇지 않을 경우 다음 중 적용 가능한 것 하나를 거쳐 변환합니다.
단, 부동소숫점 타입의 범위를 벗어나는 값을 그 부동소숫점 타입으로 변환하려고 하면 (같은 타입으로 변환하더라도) 아래의 규칙을 무시하고 그 값을 강제로 잘라내 표현 가능한 범위로 만듭니다.
목록 펼치기
- 아무 타입에서
void로- 변환되는 식을 평가만 한 뒤 버립니다.
- 사용해야 하는 값을 사용하지 않았다는 컴파일러 경고를 어쩔 수 없이 우회해야 한다면 이 방법을 사용하면 됩니다.
- 포인터끼리
- 아무 개체 타입의 포인터끼리 변환할 수 있습니다.
- 단, 변환한 포인터의 정렬이 잘못되어 있을 때는 비정의 동작이 됩니다.
- 특히 임의의 문자 타입의 포인터로 변환할 수 있으며, 이 방법으로 개체의 메모리상 표현을 확인하거나
memcpy/memmove로 복사할 수 있습니다.
- 아무 함수 타입의 포인터끼리 변환할 수 있습니다.
- 이렇게 변환된 포인터로 호환되지 않는 함수를 호출하려고 하면 비정의 동작이 됩니다.
void *의 변환과 같이 기존 포인터를 변환했다가 돌려놓았을 때 비정의 동작이 일어나지 않는다면 그 포인터 값은 원래와 같습니다.- 널 포인터를 변환한 결과는 항상 널 포인터입니다.
- 아무 개체 타입의 포인터끼리 변환할 수 있습니다.
- 정수에서 포인터로
- 구현체에서 정의하는 방법으로 변환됩니다. 변환된 결과가 올바른 포인터라는 보장은 없습니다.
- 포인터에서 정수로
- 구현체에서 정의하는 방법으로 변환됩니다. 널 포인터가 0으로 변환된다는 보장은 없습니다.
- 단, 목표 타입이 나타낼 수 없는 값으로 변환하려고 하면 비정의 동작이 됩니다.
- 구현체에서 정의하는 방법으로 변환됩니다. 널 포인터가 0으로 변환된다는 보장은 없습니다.
C99 복합 리터럴*compound literals
복합 리터럴은 초기화할 때와 동일한 대괄호 문법을 통해 무기명의 개체를 생성하는 문법입니다. 단, 가변 수식 타입의 개체는 생성할 수 없습니다.
static struct Foo {
int foo;
} foo;
void fn(void) {
// ✅ 구조체 타입을 가지는 `foo`에 복합 리터럴을 통해 새로운 값을 대입했습니다.
foo = (struct Foo){ 123 };
// ✅ `bar`에 복합 리터럴을 통해 `int` 값을 대입했습니다.
int bar = (int){ 1 };
// ✅ `baz`에 복합 리터럴을 통해 무기명 배열을 가리키는 포인터를 대입했습니다.
double *baz = (double [3]){ 3.14, 3.15, 3.16 };
// ❌ 복합 리터럴을 통해 가변 길이 배열을 생성할 수 없습니다.
(char [bar]){};
}복합 리터럴은 좌측값이므로 좌측값 맥락에서 자유롭게 사용할 수 있습니다.
// ✅ 복합 리터럴의 주소를 획득할 수 있습니다.
&(int){};
// ✅ 복합 리터럴에 쓰기 연산을 할 수 있습니다.
(char){ 'e' } = 'a';C23부터는 복합 리터럴에도 기억 부류 지정자를 지정할 수 있으며, 이렇게 생성한 개체는 일반적인 선언문을 통해 같은 기억 부류 지정자, 같은 타입, 같은 초기화 값으로 선언한 것처럼 동작합니다. 잘못 사용하면 할당과 관련된 오류를 일으킬 수 있음에 유의해야 합니다.
int *a;
for(int i = 0; i < 100; i++) {
// `for`문 안에서 `int _temp = { i }; a = &_temp;`를 한 것처럼 동작합니다.
a = &(int){ i };
// 이 시점에서 `auto`인 `(int){ i }`의 할당이 해제되고, `a`는 댕글링 포인터가 됩니다.
}
// 🔥 UB: 할당이 해제된 개체에 접근할 수 없습니다.
*a;
// ❌ `register`인 `int`의 주소를 획득할 수 없습니다.
// `register int _temp = { 1 }; &_temp;`처럼 동작합니다.
&(register int){ 1 };C11 제네릭 선택*generic selection
C에도 의외로 타입 제네릭 연산을 지원하는 언어 기능이 있습니다. _Generic() 안에 식('제어식controlling expression'이라고 합니다)과 몇 가지 타입에 따라 원하는 값을 넣으면 컴파일 시에 제어식의 타입을 확인한 뒤 일치하는 것을 선택해줍니다. 단, 일치하는 타입이 없으면 컴파일 오류가 됩니다.
// ✅ `"long long"`이 선택되었습니다.
char *type_str = _Generic(
123ll,
int: "int",
long: "long",
long long: "long long"
);
// ❌ `char *` 타입의 `"troll"`이 `int`와 일치하지 않습니다.
char *type_str_2 = _Generic(
"troll",
int: "int"
);함수나 가변 수식 타입을 선택하거나 호환되는 타입을 중복으로 작성할 수는 없습니다.
// ❌ 가변 수식 타입인 `int (*)[n]`을 선택할 수 없습니다.
int n = 3, arr[n][n];
_Generic(
arr,
int (*)[n]: "int (*)[*]"
);
// ❌ 호환되는 타입인 `int`와 `signed` (aka `int`)를 동시에 작성할 수 없습니다.
_Generic(
1,
int: "int",
signed: "signed"
);제어식은 값 변형을 거치기 때문에 최상위 한정자, 배열, 함수 타입은 사용할 수 없고 대신 포인터 타입을 사용해야 합니다.
void foo(int);
int bar[3];
const int baz;
const int *quux;
// `void (int)`를 주석 처리할 경우 `"decayed"`가 선택됩니다.
_Generic(
foo,
// ❌ 함수 타입인 `void (int)`를 선택할 수 없습니다.
void (int): "undecayed",
void (*)(int): "decayed"
);
// ✅ `"decayed"`가 선택됩니다.
_Generic(
bar,
int [3]: "undecayed",
int *: "decayed"
);
// ✅ `"decayed"`가 선택됩니다.
_Generic(
baz,
const int: "undecayed",
int: "decayed"
);
// ✅ `const int (*)`의 `const`는 최상위 한정자가 아니므로 `"qualifier undecayed`가 선택됩니다.
_Generic(
quux,
const int *: "qualifier undecayed",
int *: "qualifier decayed"
);switch문과 비슷하게 default:를 사용해 어떤 타입과도 일치하지 않는 경우를 확인할 수 있습니다.
// ✅ `"default"`가 선택됩니다.
_Generic(
(short)1,
int: "int",
long: "long",
long long: "long long",
default: "default"
);제어식과 선택되지 않은 식은 평가되지 않으며, 제어식의 값 변형 역시 부작용을 일으키지 않습니다.
int dbg(char *msg, int x) {
printf("debug: %s\n", msg);
return x;
}
int main(void) {
// ✅ `debug: int`가 출력됩니다.
_Generic(
dbg("ctrl", 1),
int: dbg("int", 2),
long: dbg("long", 3),
long long: dbg("long long", 4)
);
}제네릭 선택 문법은 주로 매크로 함수와 같이 사용합니다. 예를 들어 cppreference.com에서는 <tgmath.h>의 cbrt 매크로의 가능한 구현으로 다음을 제시하고 있습니다.
#define cbrt(X) \
_Generic( \
(X), \
long double: cbrtl, \
default: cbrt, \
float: cbrtf \
)(X)부록: Visual Studio 서식 설정하기
이 내용은 원래 이전 블로그의 댓글에 답글로 작성했던 내용으로, 다른 독자에게도 도움이 된다고 생각해 본문으로 옮겨 적습니다.
비주얼 스튜디오는 포인터와 참조를 왼쪽 정렬(int* x;)하는 것으로 악명이 높습니다. 혹시나 제 글을 읽고 설득되셨다면, 비주얼 스튜디오 설정에서 포인터 정렬을 오른쪽으로 바꿀 수 있는 방법이 있습니다. 비주얼 스튜디오 2019/2022에 해당 설정이 있는 것을 확인했고 이전 버전에도 있는지는 잘 모르겠네요.
- 도구(T) - 옵션(O)...을 엽니다.
- 왼쪽 트리에서 텍스트 편집기 - C/C++ - 코드 스타일 - 서식 - 간격으로 들어갑니다.
- 포인터/참조 맞춤을 찾아 오른쪽 맞춤으로 변경합니다.
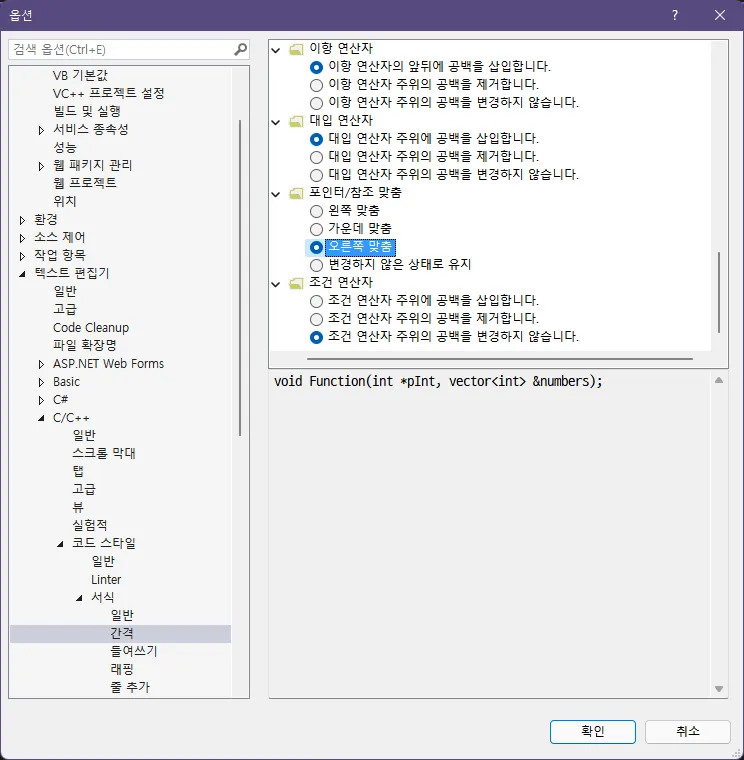
이외에도 세세한 서식 설정이 많으니 입맛대로 건드려보는 것도 좋겠습니다.
이 글을 작성하는 데 생성형 AI를 다음과 같이 사용했습니다.
간접 사용
Claude를 사용해 아래 주제에 대한 보조 조사를 진행했습니다.
- 8비트 바이트를 사용하지 않는 현대의 컴퓨터 시스템
- 컴파일러 최적화와
register키워드의 관계 - 파일 범위 선언과
extern지정자의 상호작용
다소 부끄러운 고백이지만 제가 실제로 들여쓰기 설정을 이렇게 한 적이 있었습니다. 지금은 4칸 너비의 탭을 쓰고 있습니다.
컴퓨터를 포맷해버린다고 쓰긴 했지만 실제로 자주 일어날 만한 일을 꼽자면 엉뚱한 곳에서 전혀 무관한 문제를 일으켜서 최소 몇 시간을 디버깅으로 날리게 만드는 것이 가장 유력하겠습니다.
C23의 용어집에서는 '바이트의 비트 수가 구현체 정의 값'이라는 명시적인 언급이 삭제되었지만(3.7), 부록 J의 구현체 정의 동작 목록에는 수록되어 있습니다(J.3.5/1의 (1)).
이 현상은 같은 구문을 함수 선언으로도 클래스 객체 초기화로도 읽을 수 있을 때 공통적으로 발생하는 현상이며, 제일 짜증나는 파싱*most vexing parse이라는 이름도 붙어 있습니다.
기존에는 expression을 일괄적으로 '표현식'으로 번역했지만, Hackers' Pub의 글 "expression"은 "표현식"이 아니라 그냥 "식"의 취지에 동의해 번역어를 변경했습니다. 글의 요지는 수학과 전산학 맥락에서 expression을 번역할 때 사전적 의미 중 하나인 '표현'을 추가하는 것이 오히려 부자연스러우며, '식'이라고만 번역해도 해석에 문제가 없다는 것입니다.
ISO/IEC 9899:2024 Information technology — Programming languages — C
IEEE 754-2019 IEEE Standard for Floating-Point Arithmetic